조금은 쉬운 Q&A일수도 있다
하지만 종종 면접에도 나오는 질문이기때문에 손으로 직접 실행해보면서 알아보기로 한다
Q. SELECT 쿼리문 실행 순서
일단 개발자의 숙명: 검색을 이용하면 결과는 이렇게 나온다
(요즘엔 구글링에서 프롬프팅으로 넘어가는 추세이지만...)
FROM AND JOIN
🔽
WHERE
🔽
GROUP BY
🔽
HAVING
🔽
SELECT
🔽
ORDER BY
🔽
LIMIT
테스트 테이블 & 데이터 준비
일단 이걸 검증하기 위한 employee, department_info 테이블 2개를 만들었다


예제 쿼리

이런 느낌들로 쭉 쿼리를 실행해볼 예정이다
/* FROM */
SELECT *
FROM employee;
일단 employee 테이블의 전체 데이터가 출력되는 쿼리를 실행시켰다
* 쿼리 실행결과가 에디터 내부에 나오도록 설정을 바꿔놨다

혹시라도 위처럼 설정하고 싶으신 분들은 2024.3 버전 기준으로 저곳을 찾아가서 체크하면 된다
/* WHERE */
SELECT *
FROM employee
WHERE salary > 3000;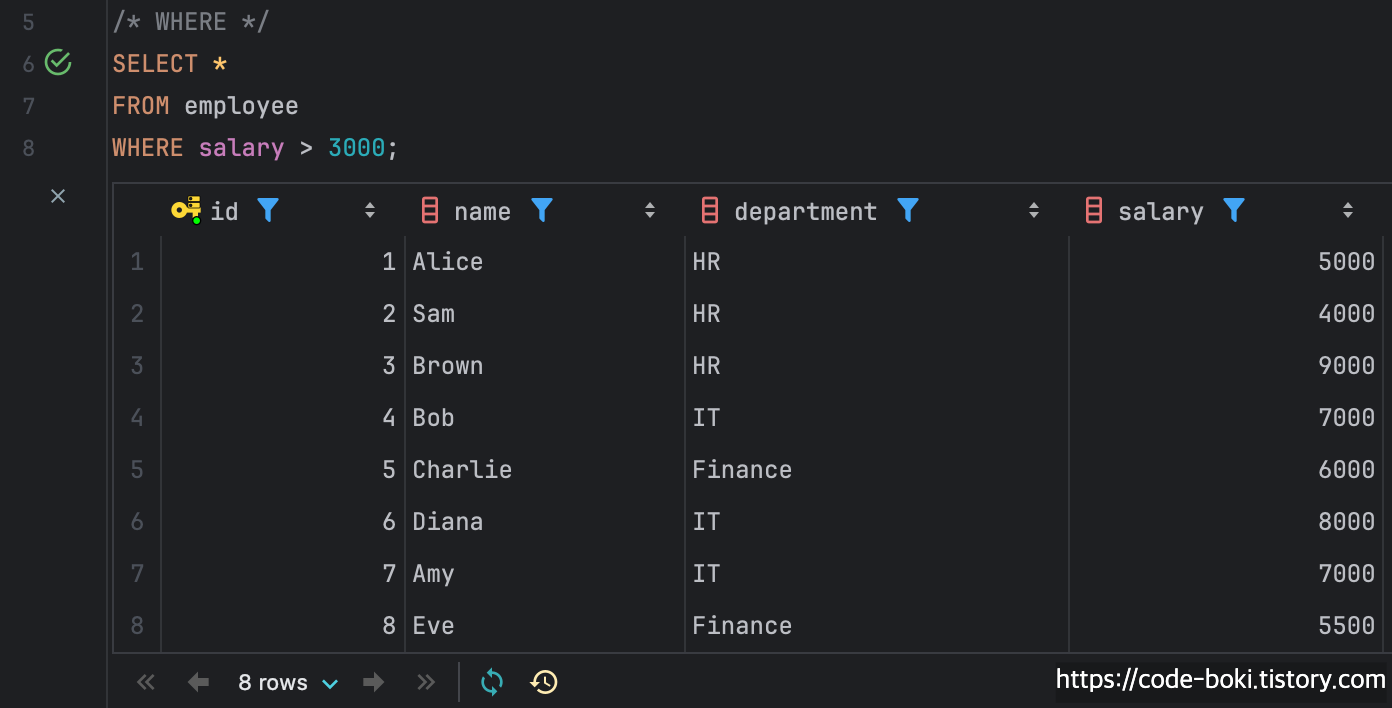
/* GROUP BY */
SELECT department, COUNT(*) AS employee_count
FROM employee
WHERE salary > 3000
GROUP BY department;

/* HAVING */
SELECT department, COUNT(*) AS employee_count
FROM employee
WHERE salary > 3000
GROUP BY department
HAVING COUNT(*) > 1;
사실 결과는 똑같다. HAVING의 조건을 > 1에서 > 2로 바꾸면 달라지겠지만 그냥 임시로 이렇게 해봤다
/* ORDER BY */
SELECT department, COUNT(*) AS employee_count
FROM employee
WHERE salary > 3000
GROUP BY department
HAVING COUNT(*) > 1
ORDER BY employee_count;
/* LIMIT */
SELECT department, COUNT(*) AS employee_count
FROM employee
WHERE salary > 3000
GROUP BY department
HAVING COUNT(*) > 1
ORDER BY employee_count
LIMIT 2;
분석
/* EXPLAIN */
EXPLAIN
SELECT department, COUNT(*) AS employee_count
FROM employee
WHERE salary > 3000
GROUP BY department
HAVING COUNT(*) > 1
ORDER BY employee_count
LIMIT 2;

Explain을 사용한 Optimizer가 예측한 MySQL 실행 계획 보기. 보기 어려우므로 json 뷰로 바꿔봤다
여기에서 주로 봐야할 건 type, possible_keys, key, Extra를 보면 될 것 같다
- type: 테이블을 접근하는 방식. 성능에 중요한 요소
- possible_keys: 쿼리에서 사용할 수 있는 인덱스 목록
- key: 실제로 선택된 인덱스
- Extra: 옵티마이저가 SQL 쿼리를 분석한 후의 실행 계획을 수립한 과정 중 추가적인 작업에 대한 설명
결과를 분석해보면
- type: "ALL" <- 테이블 전체 탐색(Table Full Scan)
- 사용가능한키, 사용된키: 없음
- Extra: where 조건 사용, group by와 having에서 임시테이블 사용, order by절에서 정렬 수행 시 인덱스를 사용하지 않고 별도의 정렬작업(filesort)를 수행함 정도로 분석할 수 있다
/* EXPLAIN */
EXPLAIN
SELECT department, COUNT(*) AS employee_count
FROM employee
# WHERE salary > 3000
WHERE id > 3
GROUP BY department
HAVING COUNT(*) > 1
ORDER BY employee_count
LIMIT 2;
where 조건을 바꿔보면 type과 key가 이전과 다른 것을 볼 수 있다
type: ALL -> RANGE
key: NULL -> PRIMARY
그러나
이 결과는 옵티마이저의 예측결과이며, 실제로 실행된 쿼리를 기반으로 결과를 제공받으려면 ANALYZE 키워드를 사용해야 한다
/* ANALYZE */
EXPLAIN ANALYZE
SELECT department, COUNT(*) AS employee_count
FROM employee
WHERE salary > 3000
GROUP BY department
HAVING COUNT(*) > 1
ORDER BY employee_count
LIMIT 2;
실제 실행된 쿼리의 실행 계획 및 성능 데이터를 출력하기 위해서는 EXPLAIN와 ANALYZE 키워드를 같이 사용해야 한다
실행순서는 아래에서 위로 보면 된다
-> Limit: 2 row(s) (actual time=1.22..1.22 rows=2 loops=1)
-> Sort: employee_count (actual time=1.21..1.21 rows=2 loops=1)
-> Filter: (count(0) > 1) (actual time=1.14..1.14 rows=3 loops=1)
-> Table scan on <temporary> (actual time=1.1..1.1 rows=3 loops=1)
-> Aggregate using temporary table (actual time=1.1..1.1 rows=3 loops=1)
-> Filter: (employee.salary > 3000) (cost=1.05 rows=2.67) (actual time=0.905..0.968 rows=8 loops=1)
-> Table scan on employee (cost=1.05 rows=8) (actual time=0.89..0.953 rows=8 loops=1)
이제 이 글의 목적을 위해 예상쿼리 순서와 맞춰보자

- FROM AND JOIN: FROM employee
- Table scan on employee (cost=1.05 rows=8) (actual time=0.89..0.953 rows=8 loops=1)
- 테이블 전체를 순차탐색
- WHERE: WHERE salary > 3000
- Filter: (employee.salary > 3000) (cost=1.05 rows=2.67) (actual time=0.905..0.968 rows=8 loops=1)
- salary > 3000인 데이터만 선택
- GROUP BY: GROUP BY department
- Aggregate using temporary table (actual time=0.387..0.387 rows=3 loops=1)
- 그룹화된 데이터는 임시테이블에 저장
- HAVING: HAVING COUNT(*) > 1
- Filter: (count(0) > 1) (actual time=1.14..1.14 rows=3 loops=1)
- SELECT: SELECT department, COUNT(*) AS employee_count
- Table scan on <temporary> (actual time=1.1..1.1 rows=3 loops=1)
- ORDER BY: ORDER BY employee_count
- Sort: employee_count (actual time=1.21..1.21 rows=2 loops=1)
- LIMIT: LIMIT 2
- Limit: 2 row(s) (actual time=1.22..1.22 rows=2 loops=1)
이렇게 실제로 순차적으로 어떤 쿼리가 실행되었는지 볼 수 있었다
그리고 actual time=을 보면 누적시간을 볼 수 있는데.. 이 쿼리가 실행된 총 시간은 1.22ms인 것을 볼 수 있다
각 단계별로 실행된 시간은 다음단계-이전단계 시간을 빼야 한다
어떤 단계에서는 cost, rows도 볼 수 있는데 이 비용에 대한 것은 추후에 다룰 예정이다..!
더 알아보기
좀 더 알아보자
- 인덱스 탐색(테이블 전체 순차탐색이 아닐때)
/* ANALYZE */
EXPLAIN ANALYZE
SELECT department, COUNT(*) AS employee_count
FROM employee
WHERE id > 3
GROUP BY department
HAVING COUNT(*) > 1
ORDER BY employee_count
LIMIT 2;
아까와 다른 점은 맨 처음 FROM절이다
- 이전
-> Table scan on employee (cost=1.05 rows=8) (actual time=0.298..0.33 rows=8 loops=1)
- 현재
-> Index range scan on employee using PRIMARY over (3 < id) (cost=1.26 rows=5) (actual time=0.0741..0.0962 rows=5 loops=1)
인덱스가 걸려있지 않은 salary > 3000일때는 테이블 전체 순차탐색을 했지만 id는 클러스터링 인덱스로 자동으로 만들어지기때문에
Index range scan으로 탐색된 것을 볼 수 있다
-> Limit: 2 row(s) (actual time=0.0742..0.0745 rows=2 loops=1)
-> Sort: employee_count (actual time=0.0731..0.0733 rows=2 loops=1)
-> Filter: (count(0) > 1) (actual time=0.0577..0.0584 rows=2 loops=1)
-> Table scan on <temporary> (actual time=0.0564..0.0568 rows=2 loops=1)
-> Aggregate using temporary table (actual time=0.0546..0.0546 rows=2 loops=1)
-> Filter: (employee.id > 3) (cost=1.26 rows=5) (actual time=0.0205..0.029 rows=5 loops=1)
-> Index range scan on employee using PRIMARY over (3 < id) (cost=1.26 rows=5) (actual time=0.0191..0.0271 rows=5 loops=1)총 걸린 시간은 0.298..0.33ms => 0.0191..0.0271ms로 92% 상승했다
이래서 인덱스를 쓰라 하는건데.. 인덱스에 관련된거는 또 다른 글에서 다룰 예정이다
- 서브쿼리
/* 추가 - SUB Query */
EXPLAIN ANALYZE
SELECT department, employee_count
FROM (SELECT department, COUNT(*) AS employee_count
FROM employee
WHERE salary > 3000
GROUP BY department
HAVING COUNT(*) > 1) AS filtered_data
ORDER BY employee_count
LIMIT 2;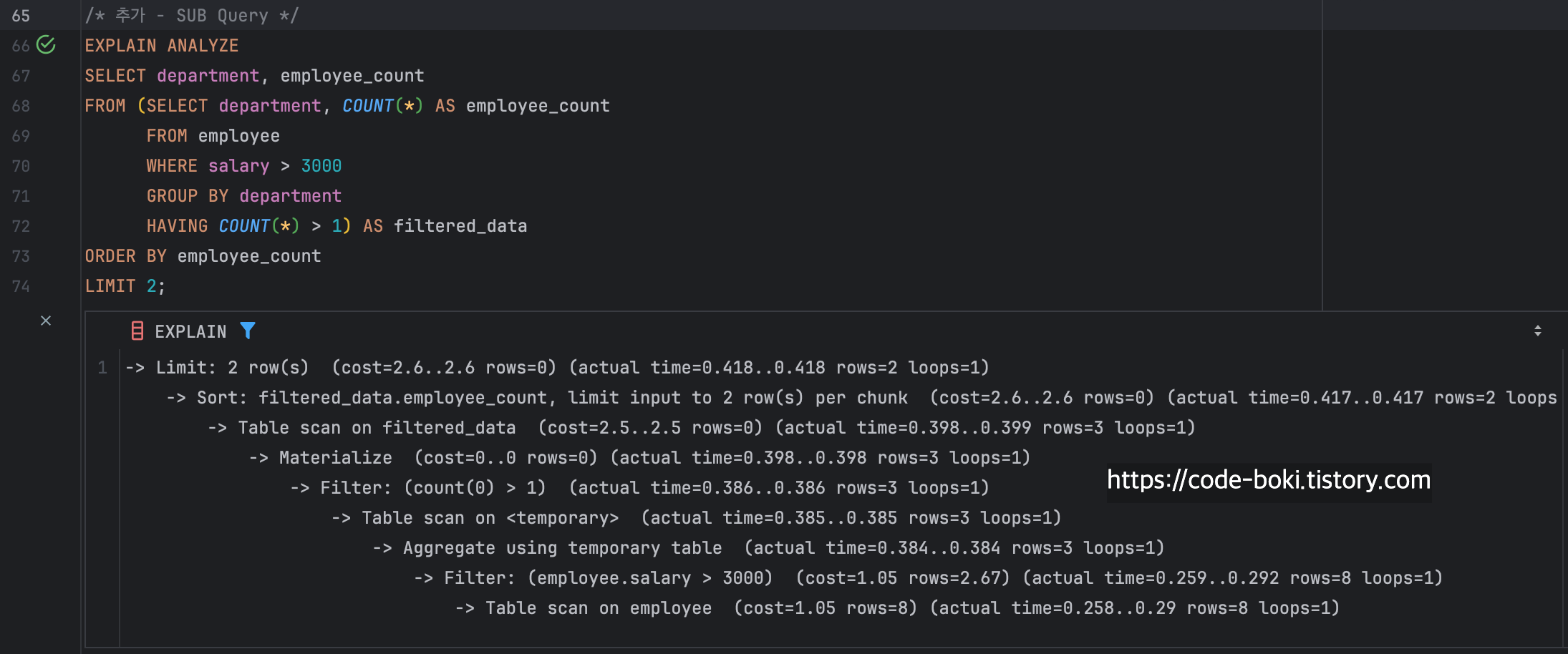
-> Limit: 2 row(s) (cost=2.6..2.6 rows=0) (actual time=0.418..0.418 rows=2 loops=1)
-> Sort: filtered_data.employee_count, limit input to 2 row(s) per chunk (cost=2.6..2.6 rows=0) (actual time=0.417..0.417 rows=2 loops=1)
-> Table scan on filtered_data (cost=2.5..2.5 rows=0) (actual time=0.398..0.399 rows=3 loops=1)
-> Materialize (cost=0..0 rows=0) (actual time=0.398..0.398 rows=3 loops=1)
-> Filter: (count(0) > 1) (actual time=0.386..0.386 rows=3 loops=1)
-> Table scan on <temporary> (actual time=0.385..0.385 rows=3 loops=1)
-> Aggregate using temporary table (actual time=0.384..0.384 rows=3 loops=1)
-> Filter: (employee.salary > 3000) (cost=1.05 rows=2.67) (actual time=0.259..0.292 rows=8 loops=1)
-> Table scan on employee (cost=1.05 rows=8) (actual time=0.258..0.29 rows=8 loops=1)이번에는 FROM 하위로 서브쿼리로 실행해봤다
이전과 달라진 점은 SELECT절이다
- 이전
-> Table scan on <temporary> (actual time=1.1..1.1 rows=3 loops=1)
- 현재
-> Table scan on filtered_data (cost=2.5..2.5 rows=0) (actual time=0.398..0.399 rows=3 loops=1)
-> Materialize (cost=0..0 rows=0) (actual time=0.398..0.398 rows=3 loops=1)서브쿼리의 결과를 임시테이블로 만들고 임시/가상 테이블을 만들어 재사용한다
이 과정이 추가되었기때문에 또 달라진 점이 있다
실행 시간이 늘어났다는 점이다!
이번에는 총 걸린 시간이 0.298..0.33ms => 0.418..0.418ms로 33% 하락했다
서브쿼리는 이렇게 데이터 크기가 작은데도 어느정도 성능 감소가 있다
꼭 써야할 상황에서만 사용하고, JOIN, WITH 구문, VIEW 테이블 등으로 대체하는 것도 고려해볼 만하다
- JOIN 절 사용
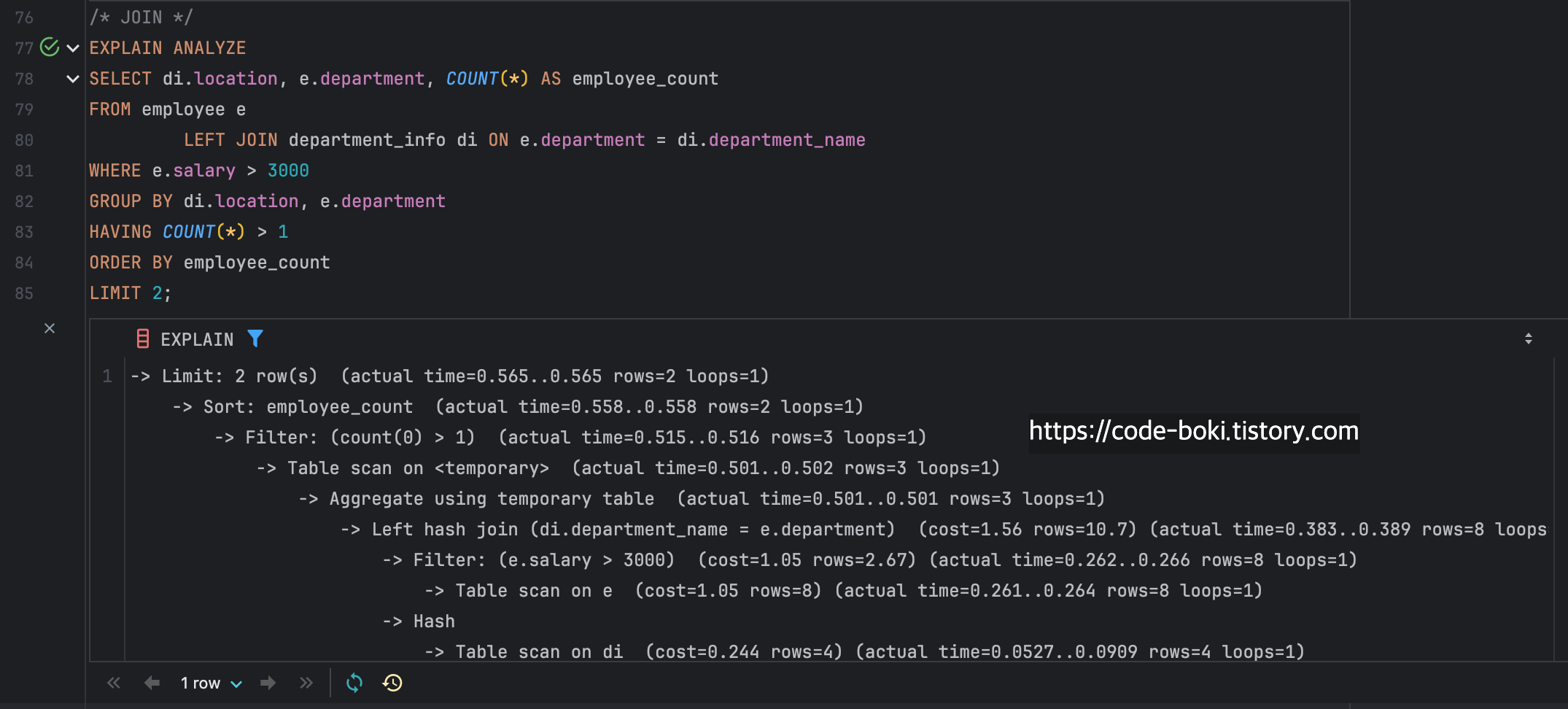
/* JOIN */
EXPLAIN ANALYZE
SELECT di.location, e.department, COUNT(*) AS employee_count
FROM employee e
LEFT JOIN department_info di ON e.department = di.department_name
WHERE e.salary > 3000
GROUP BY di.location, e.department
HAVING COUNT(*) > 1
ORDER BY employee_count
LIMIT 2;
-> Limit: 2 row(s) (actual time=0.565..0.565 rows=2 loops=1)
-> Sort: employee_count (actual time=0.558..0.558 rows=2 loops=1)
-> Filter: (count(0) > 1) (actual time=0.515..0.516 rows=3 loops=1)
-> Table scan on <temporary> (actual time=0.501..0.502 rows=3 loops=1)
-> Aggregate using temporary table (actual time=0.501..0.501 rows=3 loops=1)
-> Left hash join (di.department_name = e.department) (cost=1.56 rows=10.7) (actual time=0.383..0.389 rows=8 loops=1)
-> Filter: (e.salary > 3000) (cost=1.05 rows=2.67) (actual time=0.262..0.266 rows=8 loops=1)
-> Table scan on e (cost=1.05 rows=8) (actual time=0.261..0.264 rows=8 loops=1)
-> Hash
-> Table scan on di (cost=0.244 rows=4) (actual time=0.0527..0.0909 rows=4 loops=1)
기존과 다른점은 맨 처음 FROM AND JOIN절이다
FROM에서 Left Outer Join이 발생했기때문에 맨 아래부분의 로그가 다른 것을 확인할 수 있었다
'DB > MySQL' 카테고리의 다른 글
| RDB라고 해서 FK가 꼭 필요할까? (9) | 2024.11.13 |
|---|---|
| M1 mac mysql 설치하기 (0) | 2023.06.06 |


댓글