2월에 아버지가 돌아가시고, 장례식을 치룬 뒤의 첫 글또 글이자, 글또 10기수의 10번째 글이다..
작년 12월부터 아버지를 병간호하느라 너무 힘들었기때문에 신체적, 정신적, 시간적 여유가 없었다ㅠㅠ
목표
1. JDBC를 사용한 MySQL Connection Secure code & 수립 과정 살펴보기
2. Connection 비용
3. Spring/Springboot의 Connection Management
4. JPA(Hibernate)에서의 OSIV와 Connection과 상관관계
잡설
최근에는 JDBC Example를 검색해서 시작하는 경우가 많이 없는 느낌이다.
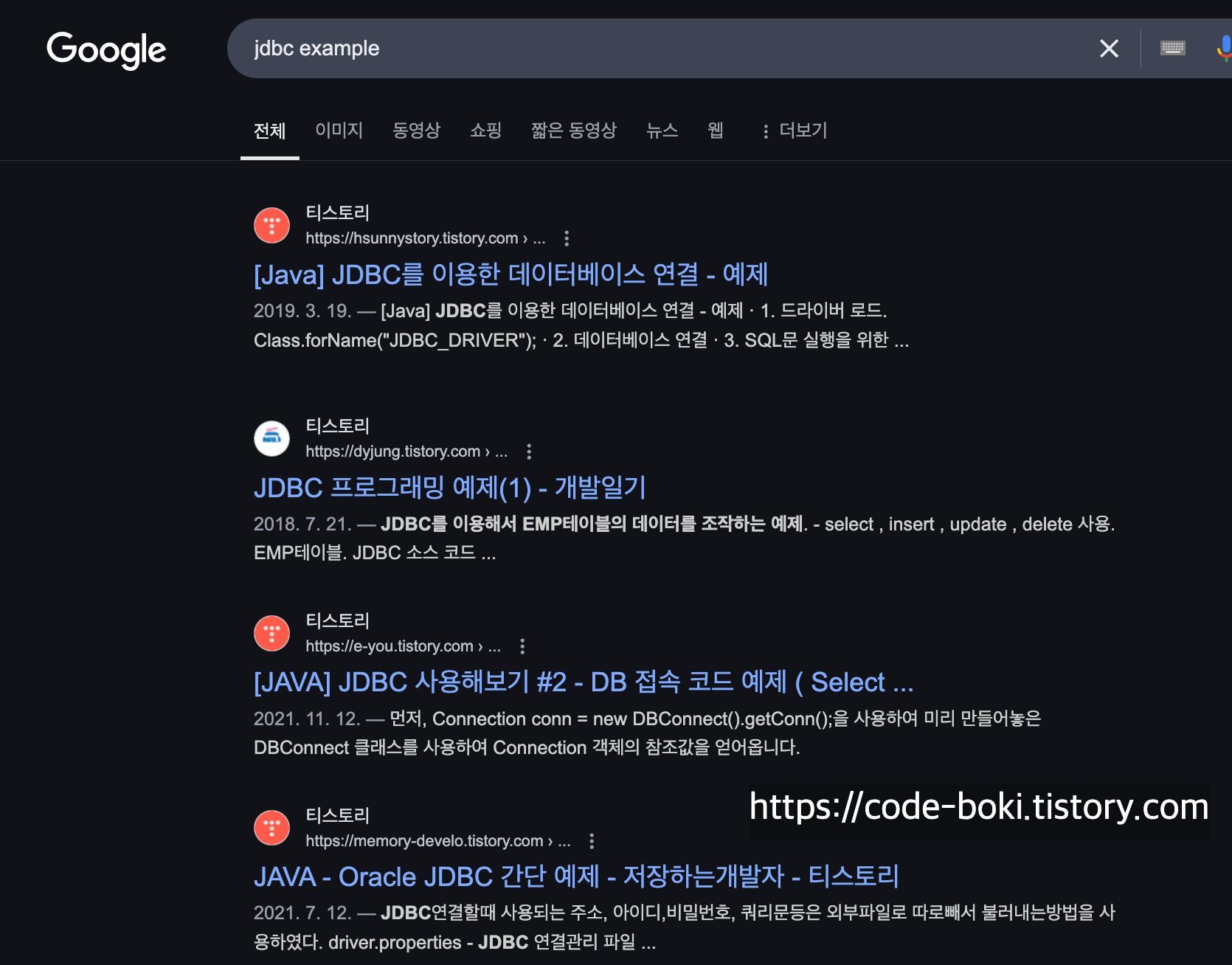
물론 Page Rank 알고리즘에 의해서 조회수가 높은 글이 나오는건 맞지만, 2018~2021년 글이 1페이지 최상단에 검색된다.
현재 2025년 3월에는 아마 JPA example이 훨씬 더 많지 않을까 한다.
10년전 비트컴퓨터 학원 수업을 들었을 때, 부트캠프라는 단어조차 없던 시절 국비학원에서는 Java수업 이후 JDBC(Java DataBase Connectivity)에 대해서 배웠다.
그 당시는 Statement vs PreparedStatement 차이점에 대해서 알면 좀 치던 시절이 있었다...ㅎ
최근에는 대학교 후배한테 자바, 백엔드 등에 대해 알려주면서 내가 중요하다고 생각하는 공부과정, 순서에 대해 알려주고 있다.
특히 어릴수록, 전공자일수록 더 낮은 수준부터 배우라고 조언을 주고 있다.
예를 들면 Springboot와 JPA 사용하기 이런 것보다는 Servlet -> Spring MVC, MySQL 쿼리/쿼리 분석/variable(configuration) 이후에 JDBC를 배우고 선택적으로 Mybatis나 JPA에 대해서 깊게 배우라고 권하고 있다.
반면, 4학년에 가깝거나 졸업을 한 경우라면 프로젝트를 하는게 우선시 되기때문에 how to use에 대한 것들이 관심사일텐데, 2학년/3학년 친구들의 경우는 CS가 왜 필요한지에 대해서 피부로 느껴지도록 how it works에 대해 알려주고 있다.
본론
1. JDBC를 사용한 MySQL Connection Secure code & 수립 과정 살펴보기
2. Connection 비용
3. Spring/Springboot의 Connection Management
4. JPA(Hibernate)에서의 OSIV와 Connection과 상관관계
# setup
미리 관계를 가진 테이블, 관계가 없는 테이블 그리고 테스트 데이터를 준비했다.
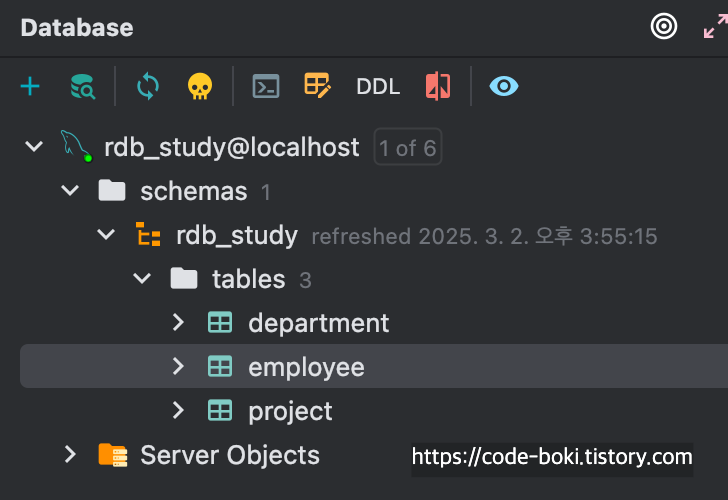
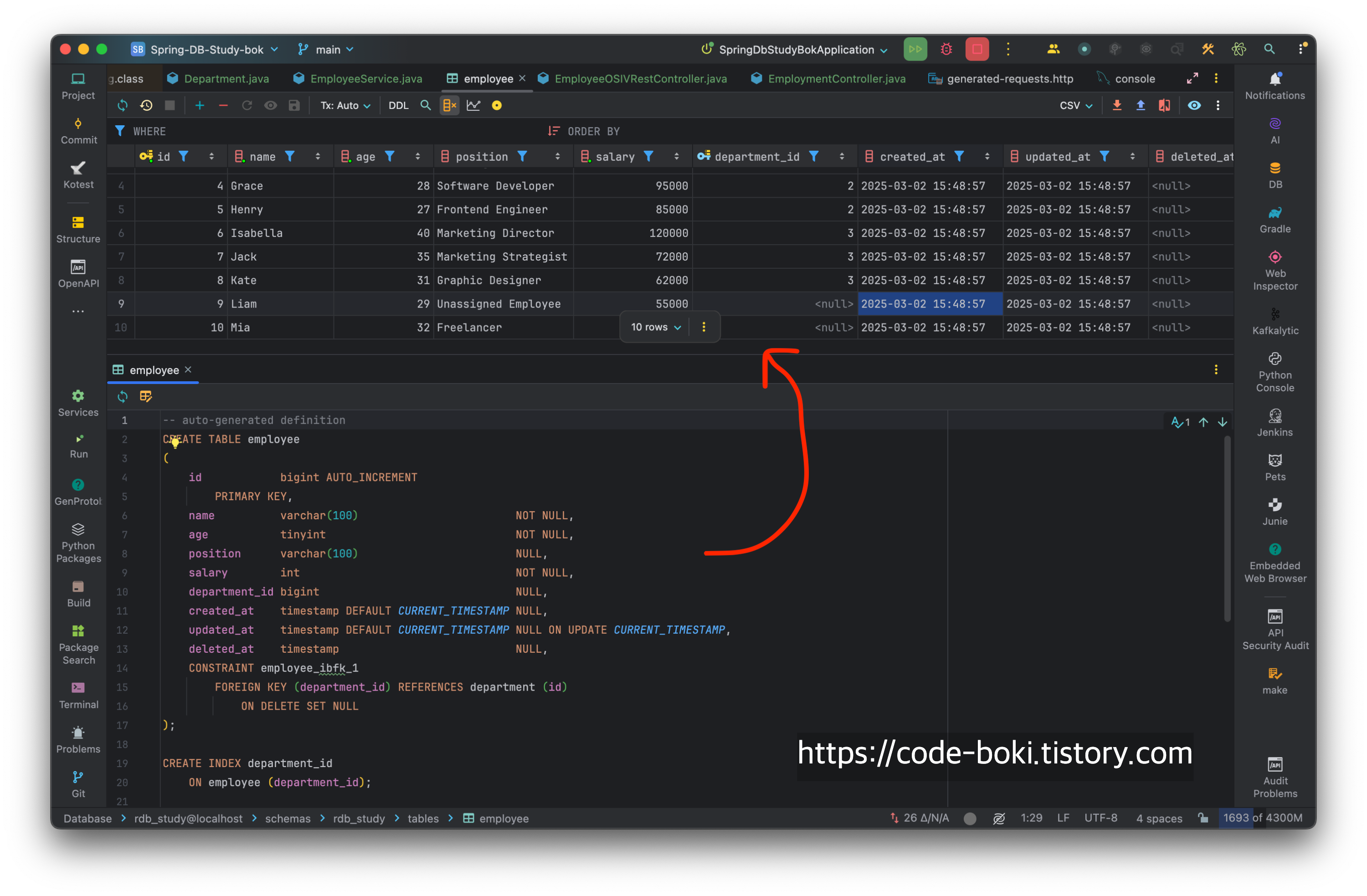
# Ex1
public class JdbcSimpleExample {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/rdb_study", "root", "rootroot");
PreparedStatement pstmt = connection.prepareStatement("SELECT id, name, position, salary FROM employee LIMIT 1");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
String position = rs.getString(3);
int salary = rs.getInt(4);
System.out.print("id = " + id + ", ");
System.out.print("name = " + name + ", ");
System.out.print("position = " + position + ", ");
System.out.println("salary = " + salary);
}
}
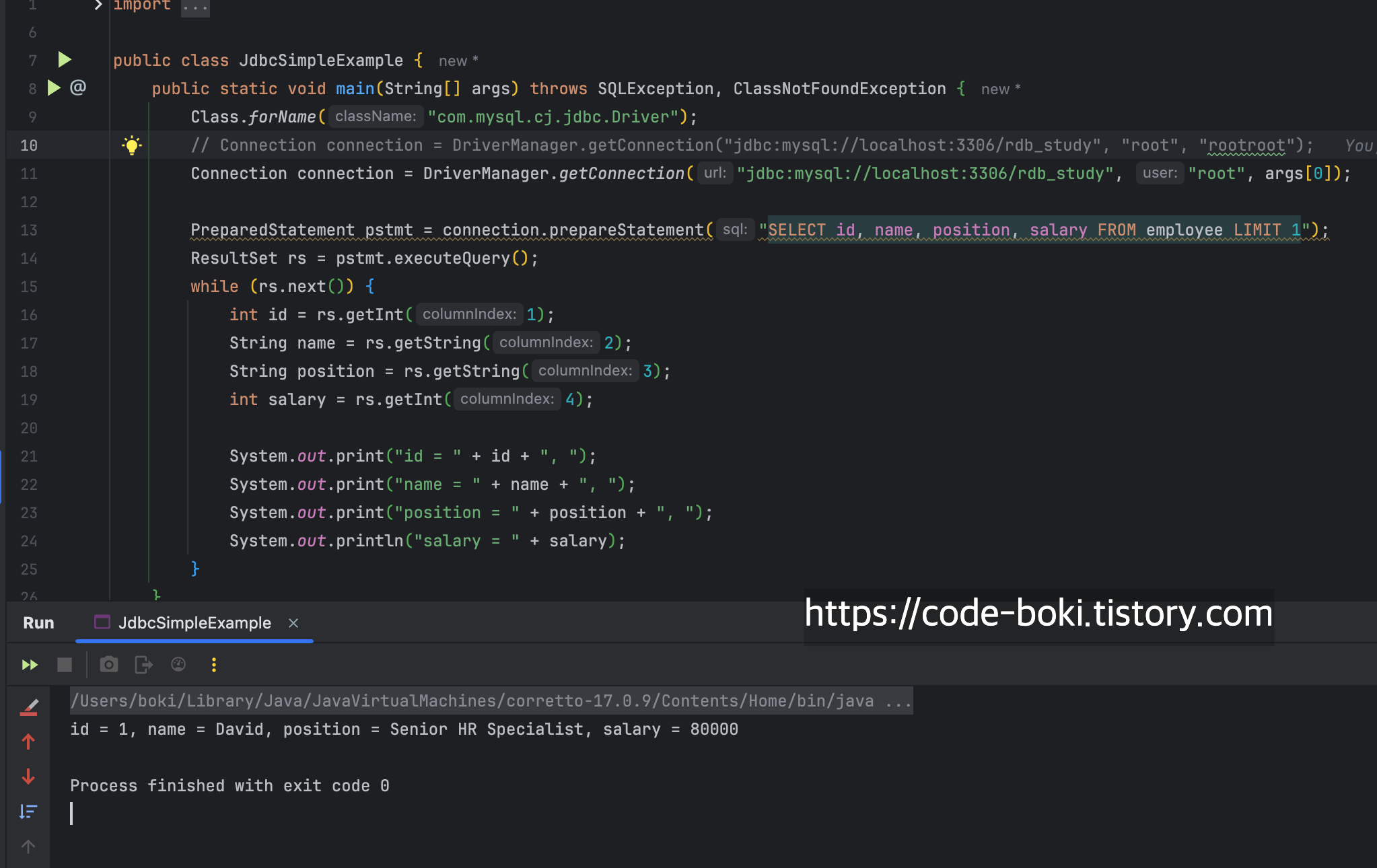
}결과
id = 1, name = David, position = Senior HR Specialist, salary = 80000
문제가 많은 코드인데, 어떤 문제들이 있는지 알아보자.
1. 접속정보 하드코딩&노출(특히 비밀번호)
2. 쿼리가 바로 인자로 전달되고 있어서 재사용이 어렵기 때문에 따로 문자로 추출해서 변수로 넘기기
3. 단순히 출력하는 과정밖에 없으므로, 응답객체를 만들어서 살짝 실제 애플리케이션과 비슷하게 출력하거나 로그로 찍어보기
4. 자원의 해제 과정이 없음
일단 1번부터 해결해보자
1번의 해결 과정은 n가지가 있다. 일단 스프링을 사용하지 않았으므로...
a. main 함수의 인자로 전달
b. 터미널(OS)로 전달된 인자
c. JVM으로 전달된 인자
이 정도를 생각해볼 수 있다. 빠르게 알아보자.
a번 방법
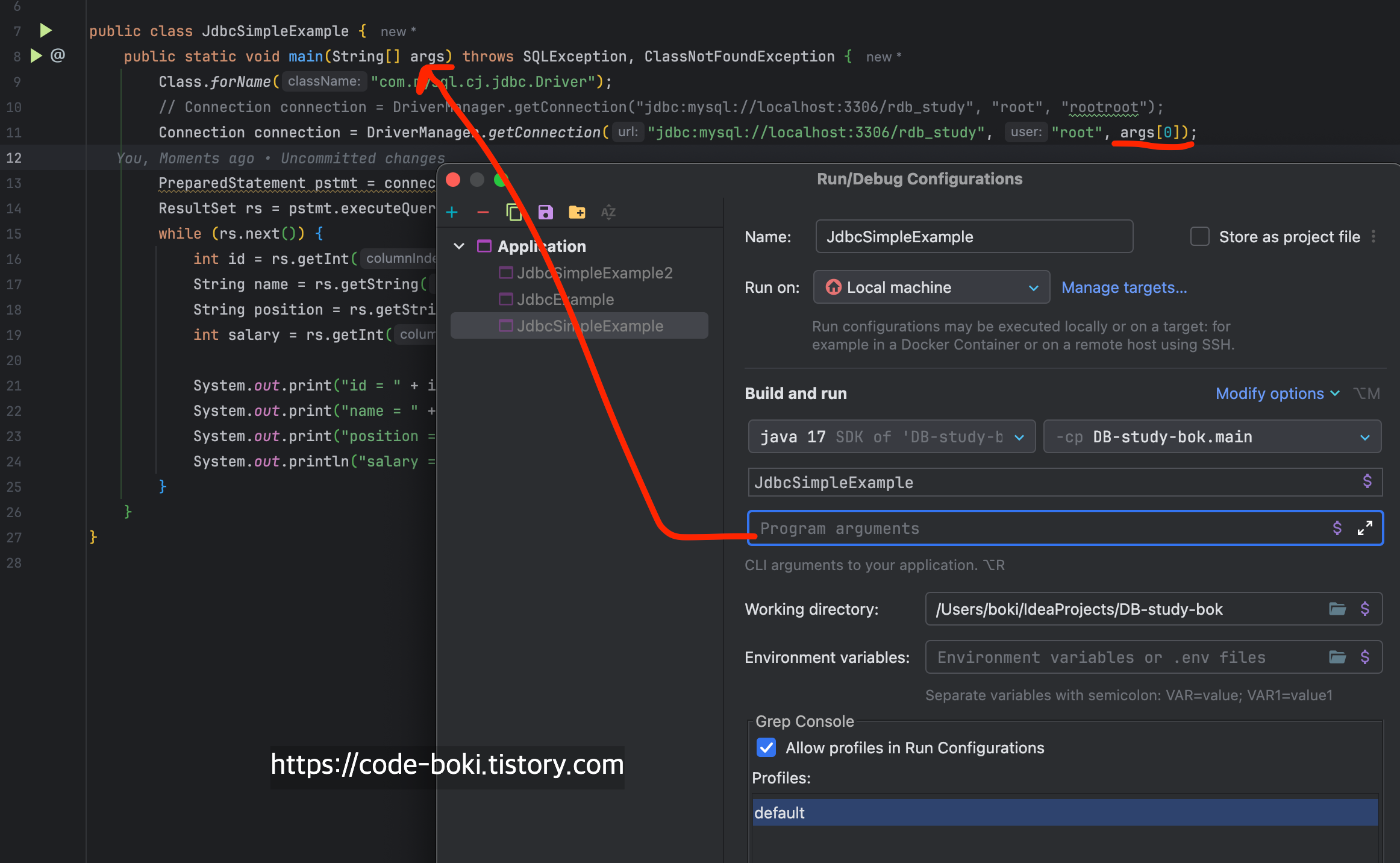
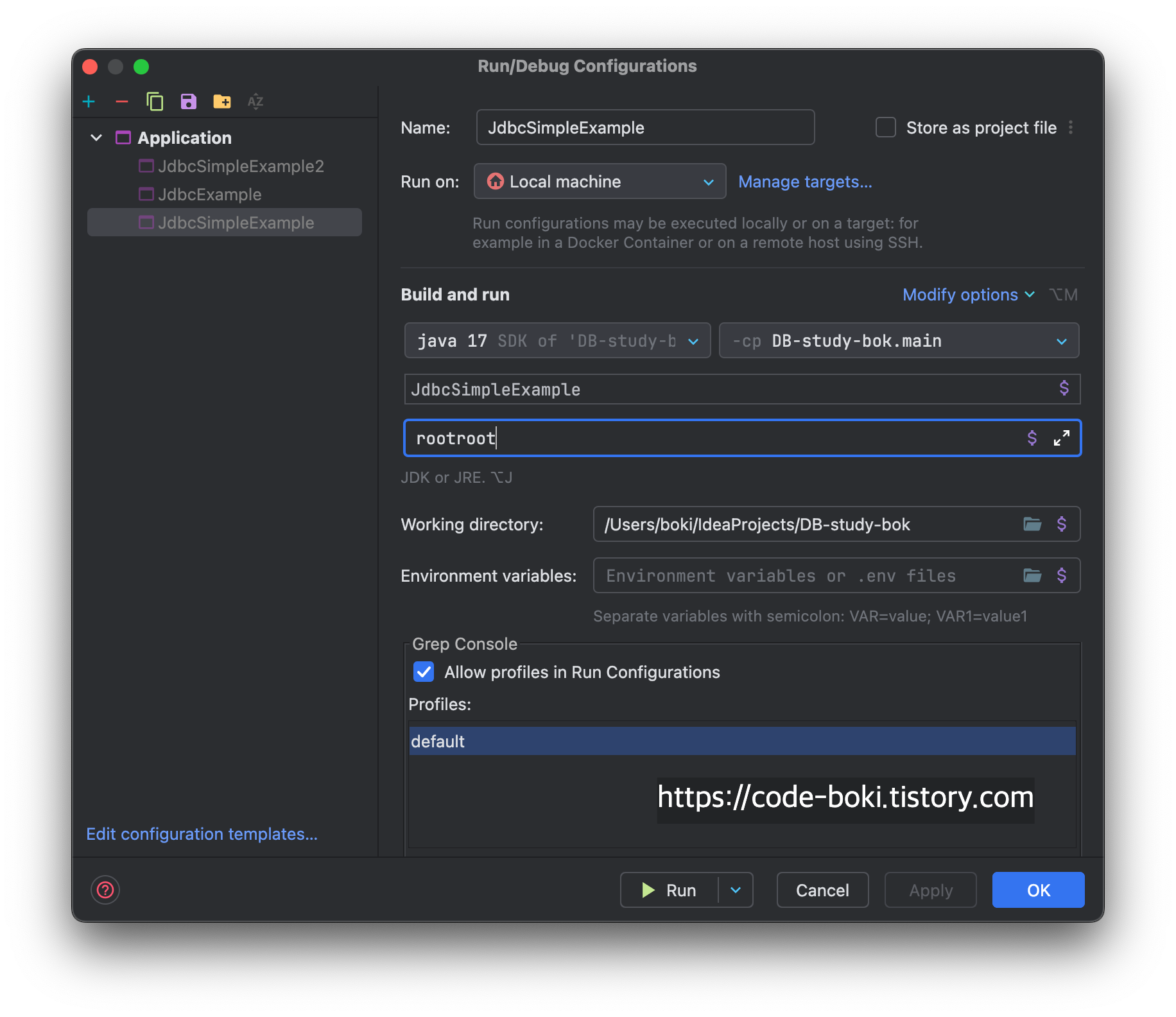
잘 된다. Spring이던 Springboot이던 최초 진입점은 main 메서드이다. 어떤 애플리케이션이든 main 메서드로 전달된 인자로 args에서 받아서 사용할 수 있는 것이다.
단점은 전부 다 String으로 넘어와서 형변환을 해줘야 한다는 점과 의미 있는 변수로 사용하려면 String password = args[0]; 등 불필요하게 변수화를 해서 써야 한다는 점이다.
뒷쪽의 의미는 b, c 방법을 보면 무슨 말인지 이해할 수 있다.
b번 방법


결과는 동일하므로 생략했다. 위의 방법과 다른 점은 key=value 형태로 변수명에 유의미한 이름을 사용할 수 있게 된 점이다.
또한 OS에서 환경변수로 넣어준다는 점이다. 리눅스 환경에서 보면 env속성과 같은 것이다.
c번 방법
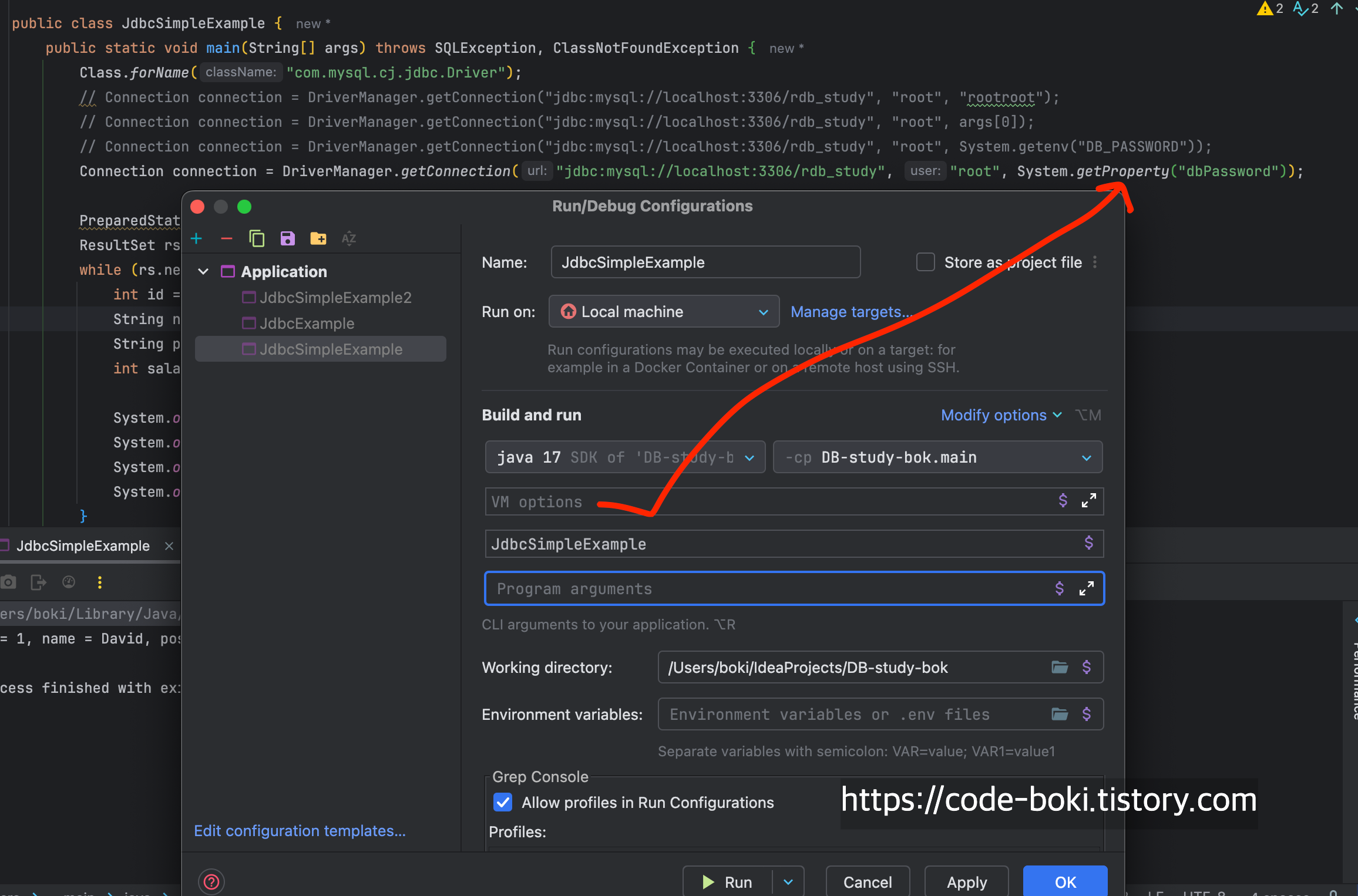
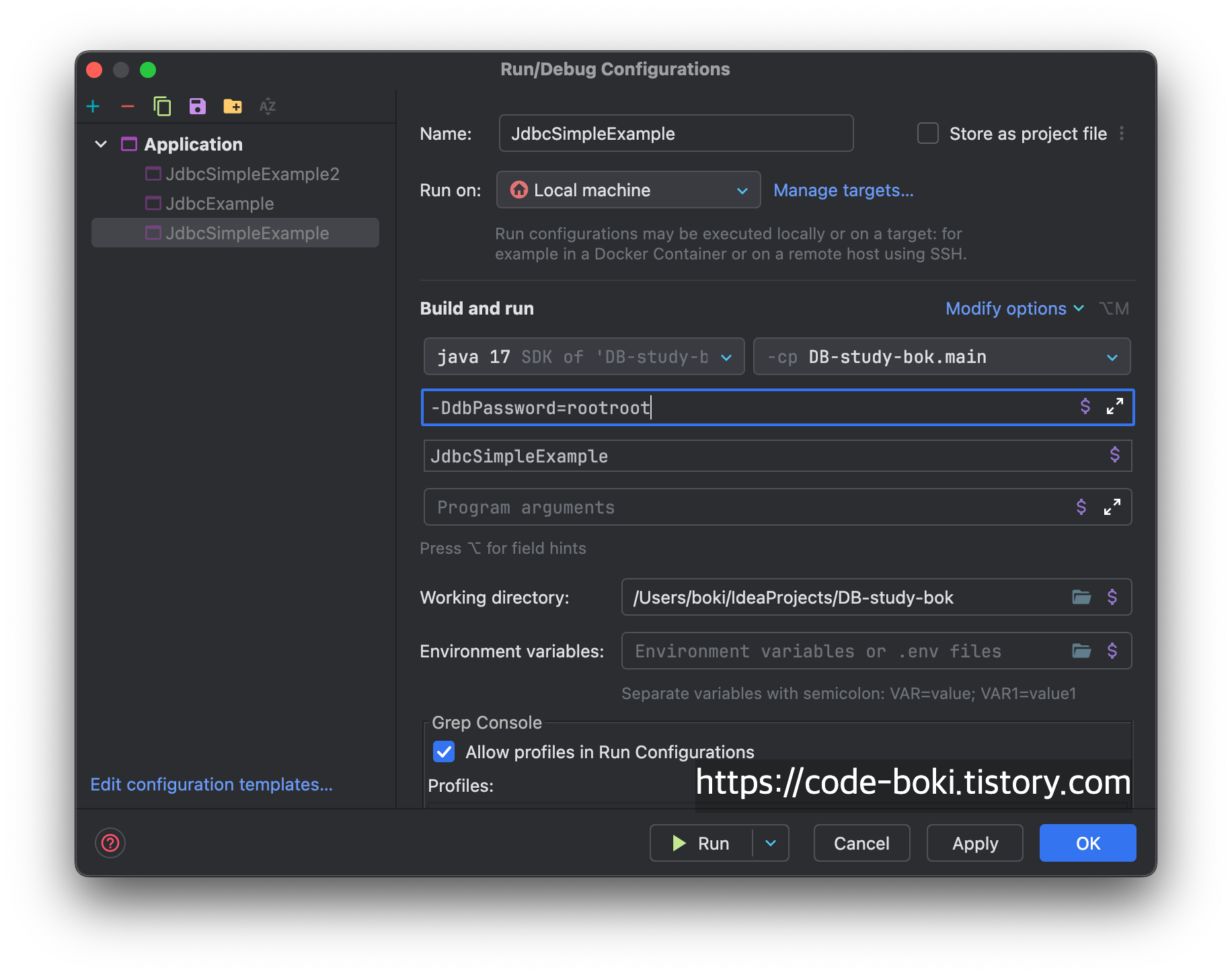
결과 스샷은 생략한다. 다른 것들과 다른 점이라면 맨 앞에 -D옵션을 붙여줘야 한다는 점이다.
아마 이게 VM 옵션인지 몰랐던 분들은 springboot에서 환경변수로 -Dspring.profiles.active=dev 이런거를 넘겨준 적이 있을 것인디, spring관련 속성을 VM으로 넘겨준 것이라고 보면 된다.
패키징된 파일이라면 java -jar XX.jar -D[키]=[값] 으로 넘겨주는 것과 같기 때문에 가장 Java Virtual Runtime 환경에 가까운 방법이라고 생각한다.
그 외에는 gradle에 파라미터 옵션을 넘겨주는 방법이 있겠다. 이 글에선 패쓰!
어쨌든 4개의 문제중 1개를 해결했다.
1. 접속정보 하드코딩&노출(특히 비밀번호)
2. 쿼리가 바로 인자로 전달되고 있어서 재사용이 어렵기 때문에 따로 문자로 추출해서 변수로 넘기기
3. 단순히 출력하는 과정밖에 없으므로, 응답객체를 만들어서 살짝 실제 애플리케이션과 비슷하게 출력하거나 로그로 찍어보기
4. 자원의 해제 과정이 없음
이어서 2번도 빠르게 해결해보자.
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/rdb_study", "root", System.getProperty("dbPassword"));
// AS-IS
// PreparedStatement pstmt = connection.prepareStatement("SELECT id, name, position, salary FROM employee LIMIT 1");
// TO-BE
final String query = "SELECT id, name, position, salary FROM employee";
PreparedStatement pstmt = connection.prepareStatement(query);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
String position = rs.getString(3);
int salary = rs.getInt(4);
System.out.print("id = " + id + ", ");
System.out.print("name = " + name + ", ");
System.out.print("position = " + position + ", ");
System.out.println("salary = " + salary);
}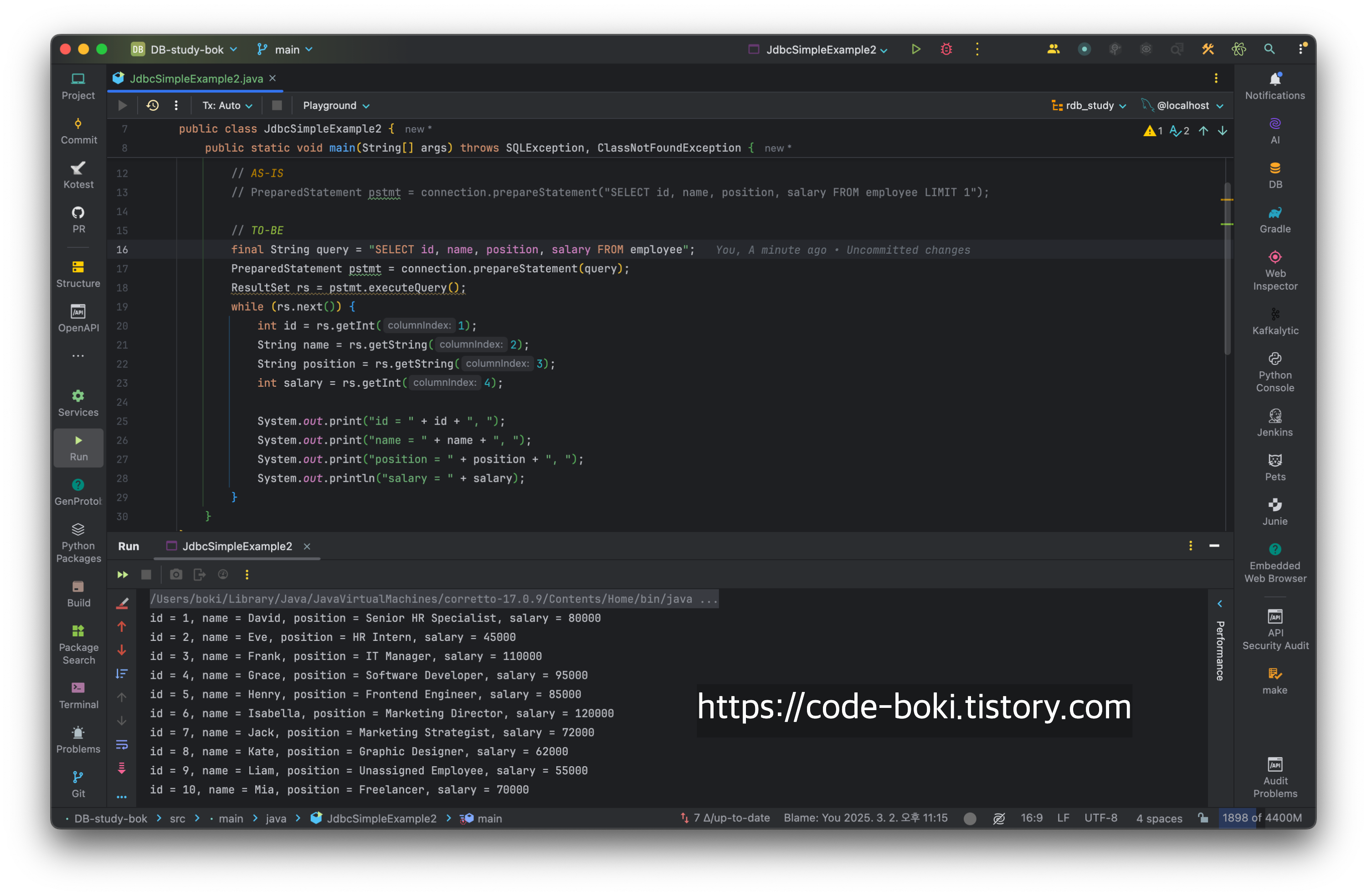
쿼리를 변수로 빼는 김에 LIMIT 1에 대한 부분도 제거하고, 쿼리 전체 결과가 나오도록 했다.
해결 완료! 이제는 저 쿼리를 재사용할 수 있게 되었다.
4개의 문제중 2개를 해결했다.
1. 접속정보 하드코딩&노출(특히 비밀번호)
2. 쿼리가 바로 인자로 전달되고 있어서 재사용이 어렵기 때문에 따로 문자로 추출해서 변수로 넘기기
3. 단순히 출력하는 과정밖에 없으므로, 응답객체를 만들어서 살짝 실제 애플리케이션과 비슷하게 출력하거나 로그로 찍어보기
4. 자원의 해제 과정이 없음
이어서 3번 고고, 빠른 개발을 위해 Lombok을 붙여서 응답객체를 만드는 작업을 했다.
@Getter
@AllArgsConstructor
@ToString
public class EmployeeResponse {
private long id;
private String name;
private String position;
private int salary;
}간단하게, Getter와 모든 인자를 갖는 생성자, 인스턴스의 정보를 모두 출력해주는 ToString을 붙였다.
JPA 사용시에는 순환참조를 조심해야 하기때문에 ToString 사용시에는 exclude를 잘 걸거나, Lombok을 안쓰거나 하면 된다.(개인적으로는 잘 쓰면 된다고 봄)
@Slf4j
public class JdbcSimpleExample {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/rdb_study", "root", System.getProperty("dbPassword"));
final String query = "SELECT id, name, position, salary FROM employee";
PreparedStatement pstmt = connection.prepareStatement(query);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
String position = rs.getString(3);
int salary = rs.getInt(4);
// To-Be
EmployeeResponse employee = new EmployeeResponse(id, name, position, salary);
log.info("employee: {}", employee);
}
}
}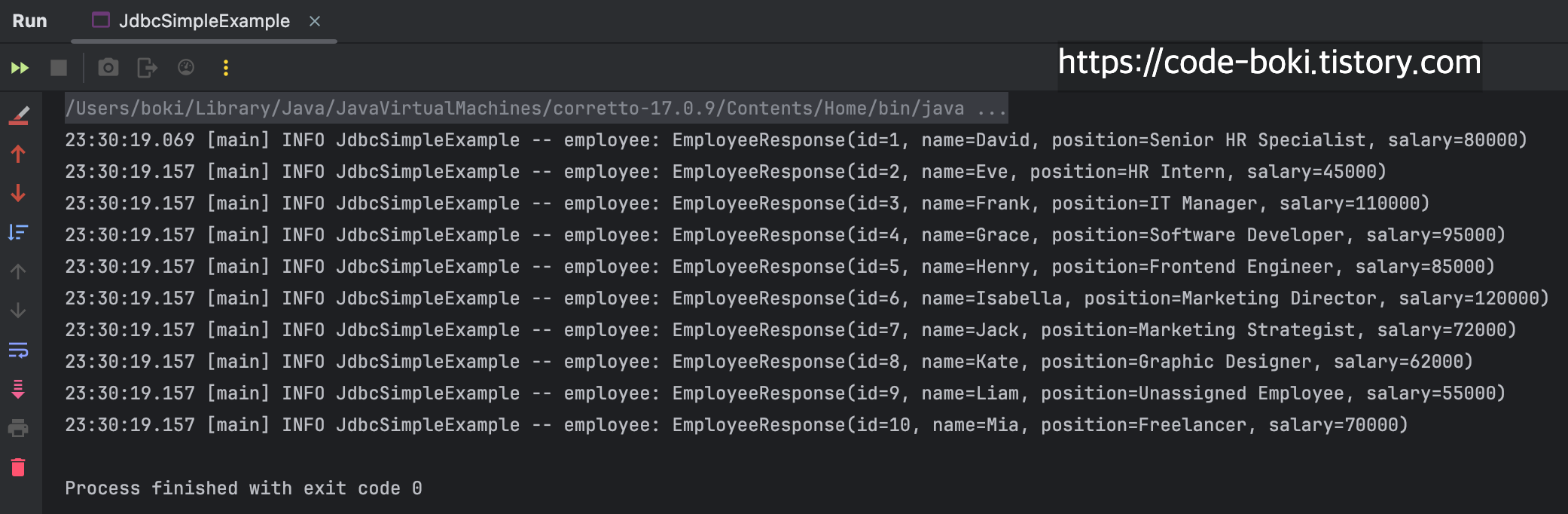
단순한 변수가 클래스라는 틀에 맞춰져 객체로 인스턴스화가 되었다.
또한 logger를 사용해 실행시간, 스레드 정보, 로그레벨, 실행되는 메서드, 로그 키/값 등이 상세히 나오게 됐다.
4개의 문제중 3개를 해결했다.
1. 접속정보 하드코딩&노출(특히 비밀번호)
2. 쿼리가 바로 인자로 전달되고 있어서 재사용이 어렵기 때문에 따로 문자로 추출해서 변수로 넘기기
3. 단순히 출력하는 과정밖에 없으므로, 응답객체를 만들어서 살짝 실제 애플리케이션과 비슷하게 출력하거나 로그로 찍어보기
4. 자원의 해제 과정이 없음
마지막 4번에 들어가기에 앞서, 현재 애플리케이션의 코드에서 의문을 품는 분들이 있을 것이다.
어? 커넥션 등..... 자원해제를 안하고 계속 사용하셨으니, 문제가 발생했던거 아닌가요!?
문제가 발생할 수 있는 코드는 맞지만, 현재 코드에서는 문제가 사실 발생하지 않는다.
진짜? 한번 살펴보자.
메인스레드가 바로 종료되지 않도록 c를 입력하면 커넥션을 맺고, r을 입력하면 쿼리가 실행되게 하고, q를 입력하면 커넥션이 종료되고, exit를 입력하면 프로세스가 종료되는 코드로 변경시켜보자.
@Slf4j
public class JdbcSimpleExample {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
Scanner scanner = new Scanner(System.in);
Connection connection = null;
while (true) {
System.out.println("입력하세요: ");
System.out.println("c - DB 연결");
System.out.println("r - Query 실행");
System.out.println("q - DB 연결 종료");
System.out.println("종료하려면 'exit' 입력");
String input = scanner.nextLine();
if (input.equalsIgnoreCase("c")) {
Class.forName("com.mysql.cj.jdbc.Driver");
if (connection == null || connection.isClosed()) {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/rdb_study", "root", System.getProperty("dbPassword"));
log.info("DB 연결 성공");
} else {
log.warn("이미 DB 연결되어있음");
}
}
else if (input.equalsIgnoreCase("r")) {
if (connection == null || connection.isClosed()) {
log.warn("DB Connection 필요");
continue;
}
log.info("Query 실행");
final String query = "SELECT id, name, position, salary FROM employee";
PreparedStatement pstmt = connection.prepareStatement(query);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
String position = rs.getString(3);
int salary = rs.getInt(4);
EmployeeResponse employee = new EmployeeResponse(id, name, position, salary);
log.info("employee: {}", employee);
}
}
else if (input.equalsIgnoreCase("q")) {
assert connection != null;
log.info("DB 연결 종료");
connection.close();
}
else if (input.equalsIgnoreCase("exit")) {
log.info("프로그램 종료");
break;
}
}
}
}
나름 많이 변경하고, 안정적으로 만든 코드다. 실행해본 결과는 잘 작동한다.
입력하세요:
c - DB 연결
r - Query 실행
q - DB 연결 종료
종료하려면 'exit' 입력
r
23:44:51.862 [main] WARN JdbcSimpleExample -- DB Connection 필요
입력하세요:
c - DB 연결
r - Query 실행
q - DB 연결 종료
종료하려면 'exit' 입력
c
23:44:54.510 [main] INFO JdbcSimpleExample -- DB 연결 성공
입력하세요:
c - DB 연결
r - Query 실행
q - DB 연결 종료
종료하려면 'exit' 입력
r
23:44:55.295 [main] INFO JdbcSimpleExample -- Query 실행
23:44:55.331 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=1, name=David, position=Senior HR Specialist, salary=80000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=2, name=Eve, position=HR Intern, salary=45000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=3, name=Frank, position=IT Manager, salary=110000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=4, name=Grace, position=Software Developer, salary=95000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=5, name=Henry, position=Frontend Engineer, salary=85000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=6, name=Isabella, position=Marketing Director, salary=120000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=7, name=Jack, position=Marketing Strategist, salary=72000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=8, name=Kate, position=Graphic Designer, salary=62000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=9, name=Liam, position=Unassigned Employee, salary=55000)
23:44:55.337 [main] INFO JdbcSimpleExample -- employee: EmployeeResponse(id=10, name=Mia, position=Freelancer, salary=70000)
입력하세요:
c - DB 연결
r - Query 실행
q - DB 연결 종료
종료하려면 'exit' 입력
q
23:44:57.016 [main] INFO JdbcSimpleExample -- DB 연결 종료
입력하세요:
c - DB 연결
r - Query 실행
q - DB 연결 종료
종료하려면 'exit' 입력
exit
23:44:59.937 [main] INFO JdbcSimpleExample -- 프로그램 종료
Process finished with exit code 0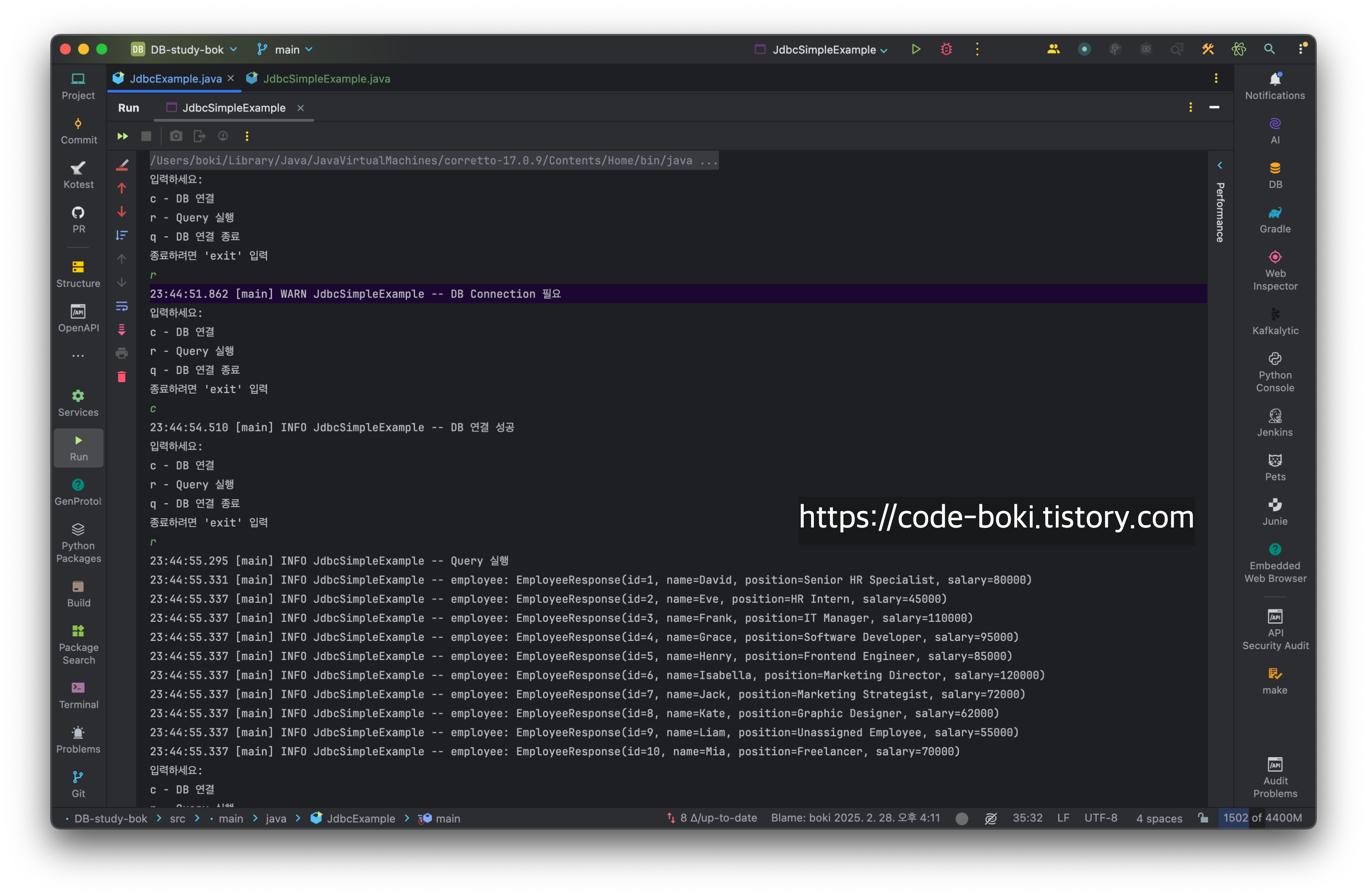
하지만 왜 finally 또는 코드의 마지막 구문에 Scanner, Connection, Statement, ResultSet에 대한 자원 해제가 없는지!?
이러면 mysql에서 커넥션을 계속 소비하지는 않을지 걱정일 것이다.
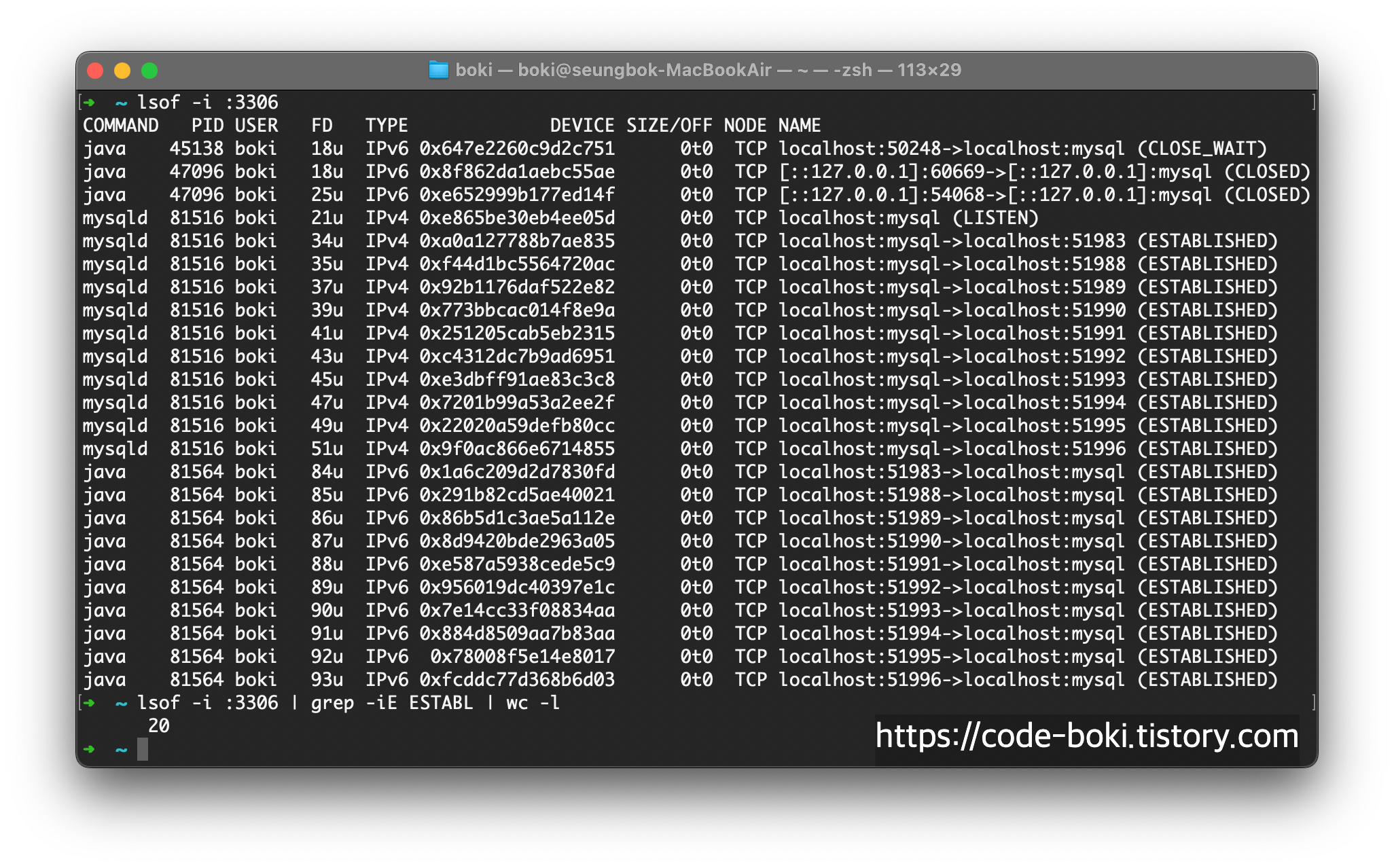
애플리케이션을 실행시키고, 아무 입력도 하지 않은 채로 homebrew로 mysql을 실행시킨 뒤 lsof로 3306 포트를 살펴보자

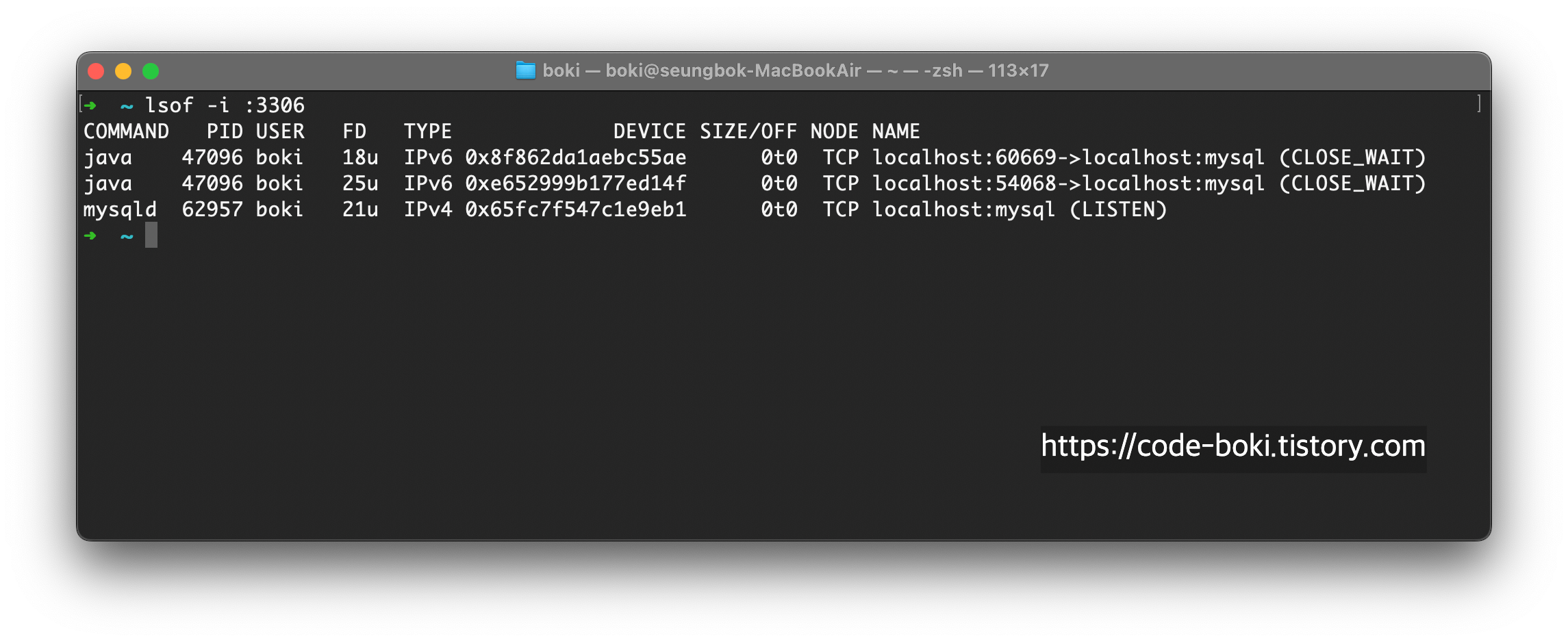
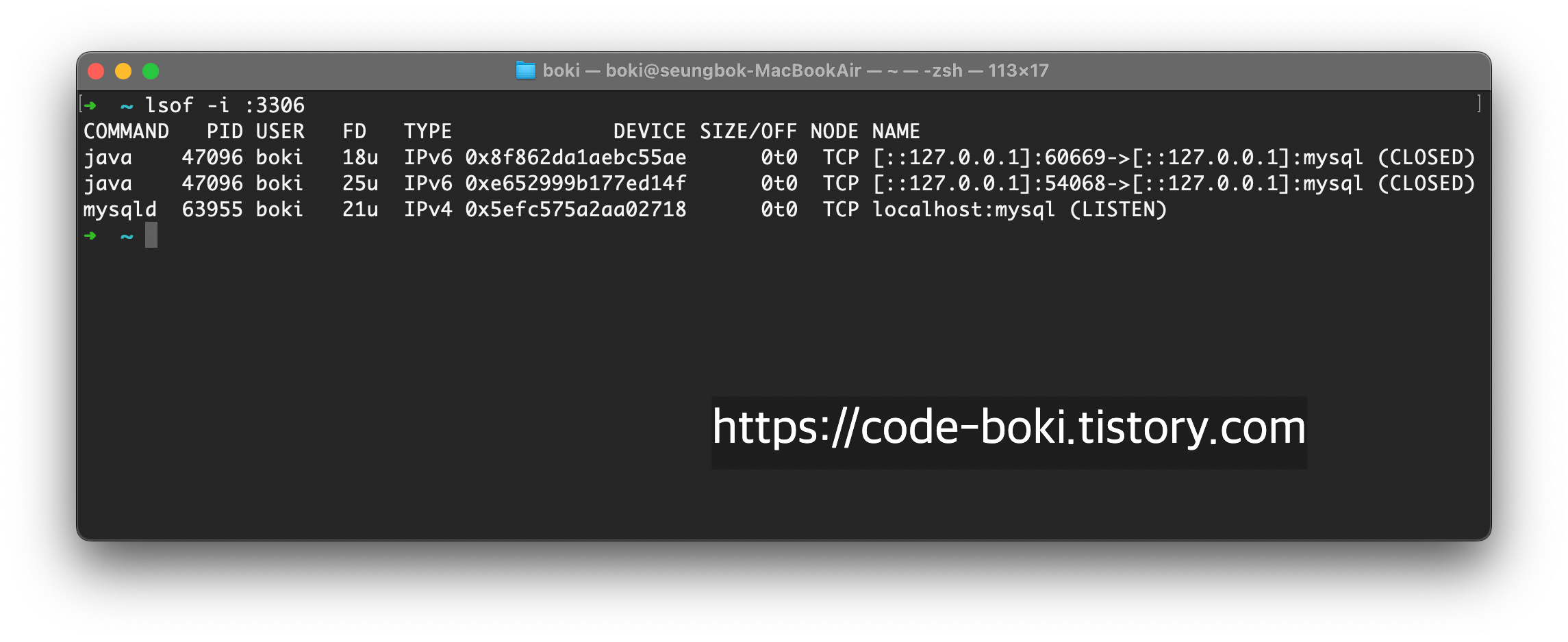
사실 위의 두 스샷에 나온 CLOSE_WAIT와 CLOSED는 이전에 연결을 수립했던 것들이 종료되는 과정이 나온 것으로... 실험에 있어선 초기상태를 잘못 셋팅했다. 하지만 TCP의 상태중 하나라는 것을 볼 수 있다.
TCP State Flowchart에 관한 링크도 첨부한다. IBM 꺼다
https://www.ibm.com/support/pages/flowchart-tcp-connections-and-their-definition
Flowchart of TCP connections and their definition
Flowchart of TCP connections and their definition
www.ibm.com
좀 더 친절한 한글 사이트는 여깄다.
https://smjeon.dev/etc/tcp-state/
TCP 상태(CLOSE_WAIT, TIME_WAIT)
트래픽을 만들어내는 어떤 툴을 사용하다가 CLOSE_WAIT 상태로 계속 유지되는 버그를 마주쳤다. 그런 의미에서 TCP 상태에 대해서 공부하고 정리한다.
smjeon.dev
이제 c를 입력해 연결을 맺어보자
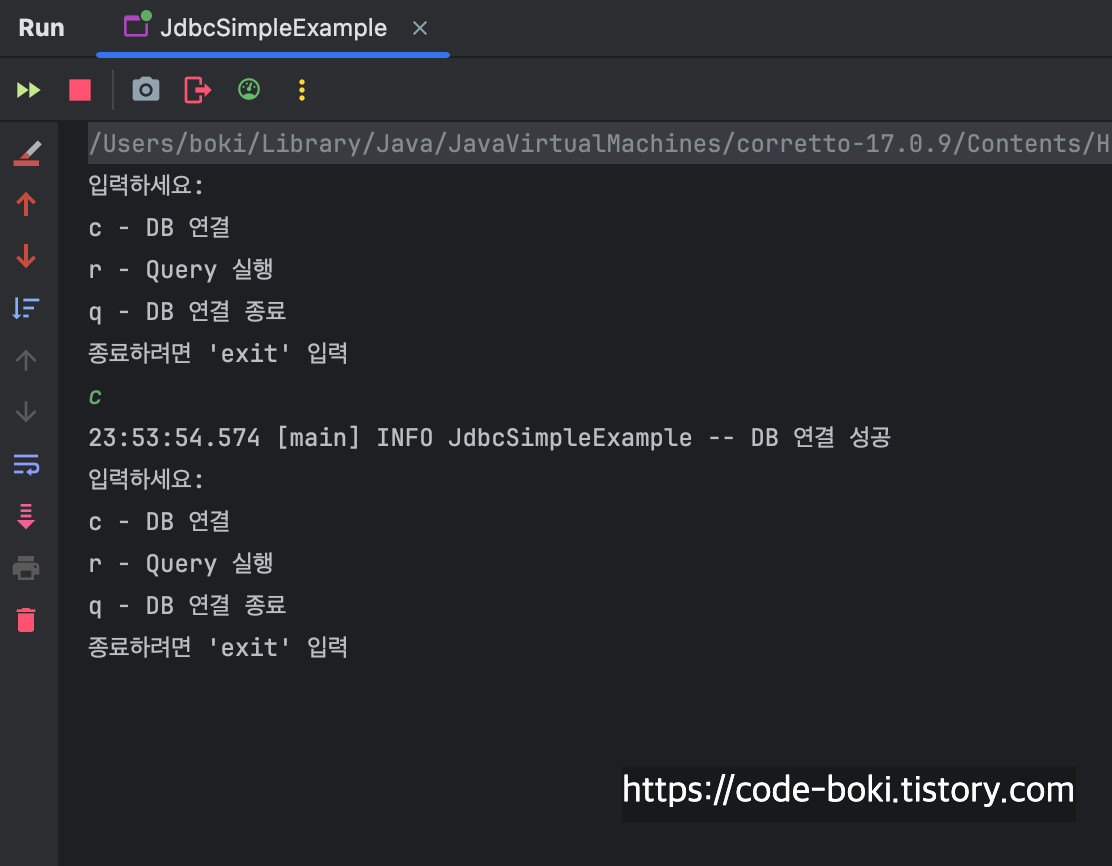

다시 grep으로 ESTABLISHED된 것들만 살펴보자
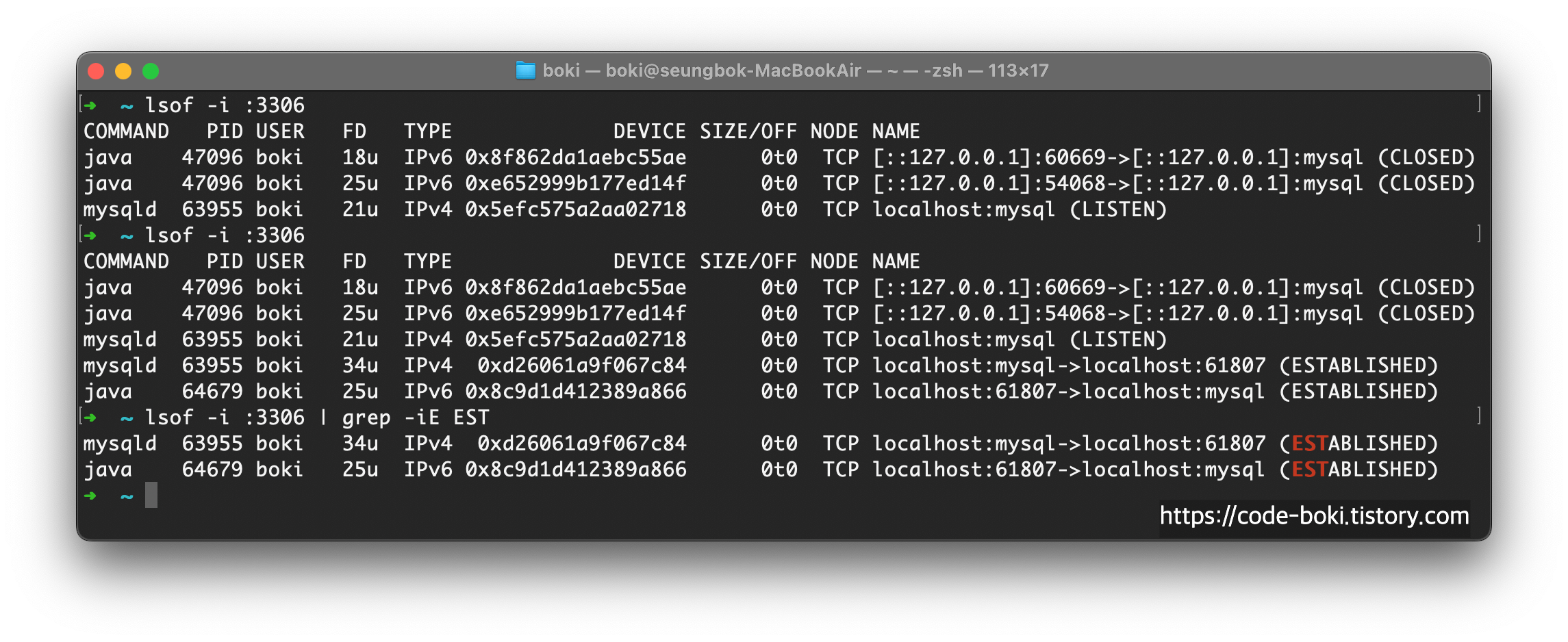
mysql 서버(mysqld)와 java 애플리케이션이 TCP로 서로 연결된 것을 알 수 있다.
FD는 파일디스크럽터를 나타내며, 쿼리가 실행되고 트랜잭션이 커밋되면 파일에 쓰기를 해야되기때문에 그 역할로 보인다.
TCP는 연결수립할때 3-way handshake, 종료할때는 4-way handshake과정을 거친다.
그럼 r을 입력해 쿼리를 실행하고, q로 연결을 종료해보자.
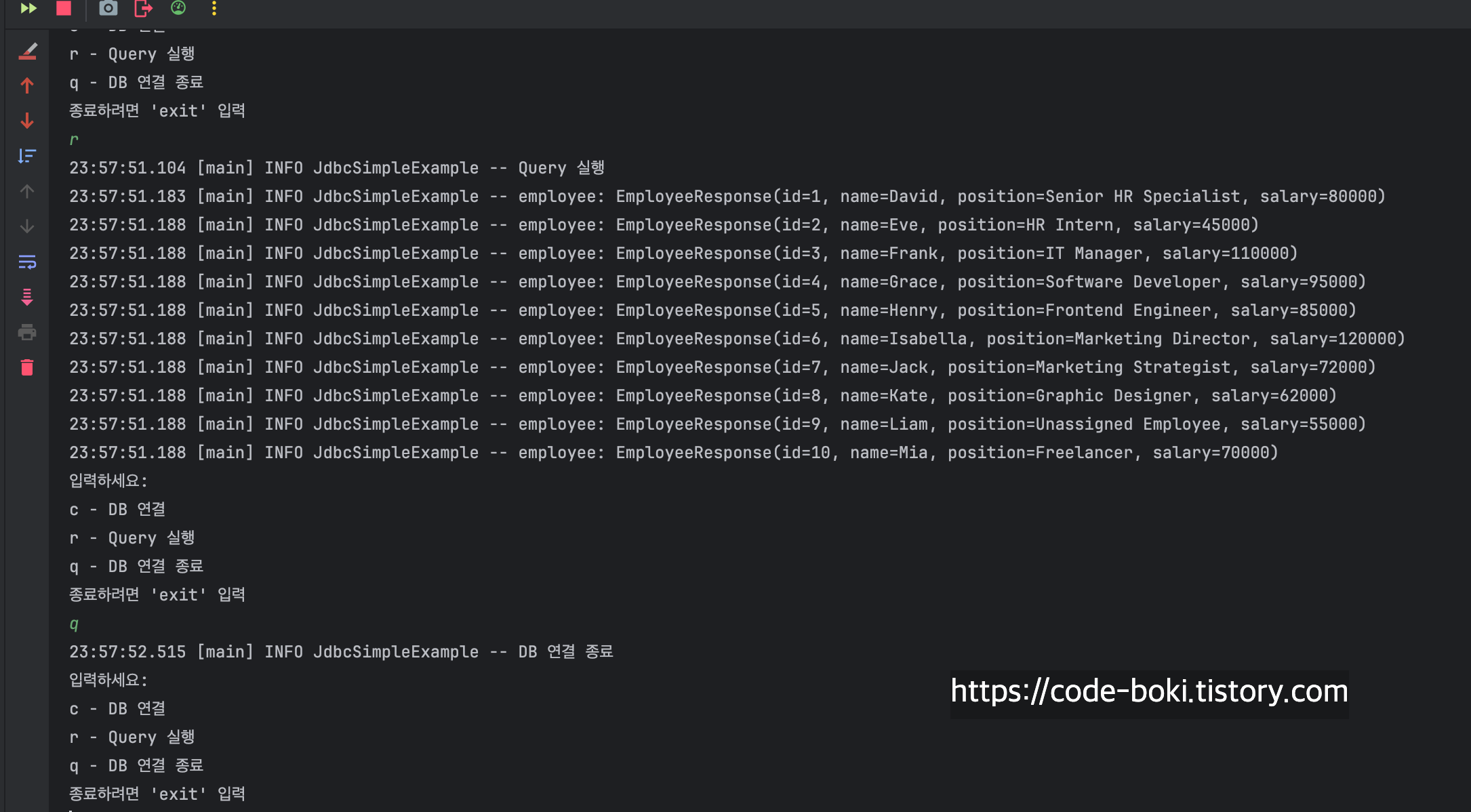
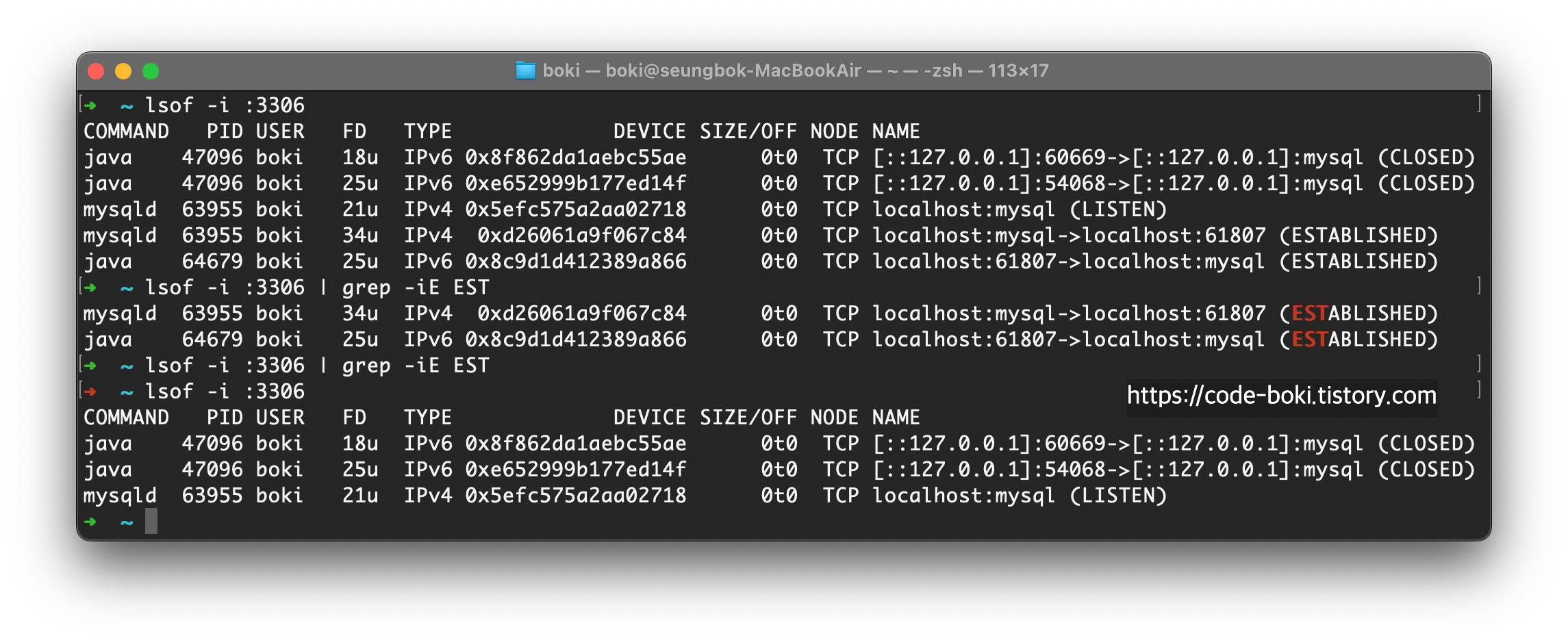
연결이 종료됐다고 나온다..!
이렇게 java 애플리케이션과 mysql 서버는 TCP로 연결을 맺는다는 사실을 알았다.
또한 서로 연결이 수립되면 mysqld와 java가 1:1로 ESTABLISHED 상태가 된다는 것도 알았다.
그럼.....만약에 q를 눌러서 DB 연결을 종료하지 않는 위험한 프로그램이 된다면 TCP 연결이 엄청 쌓일까....!?!?
이것을 실행하기 위해 q를 눌렀을 때의 자바 로직을 주석처리하고, IntelliJ에서 애플리케이션을 multiple instance 모드로 실행하고(여러 프로세스로 실행) c로 연결을 수립한 다음에 exit로 한꺼번에 종료해보자.
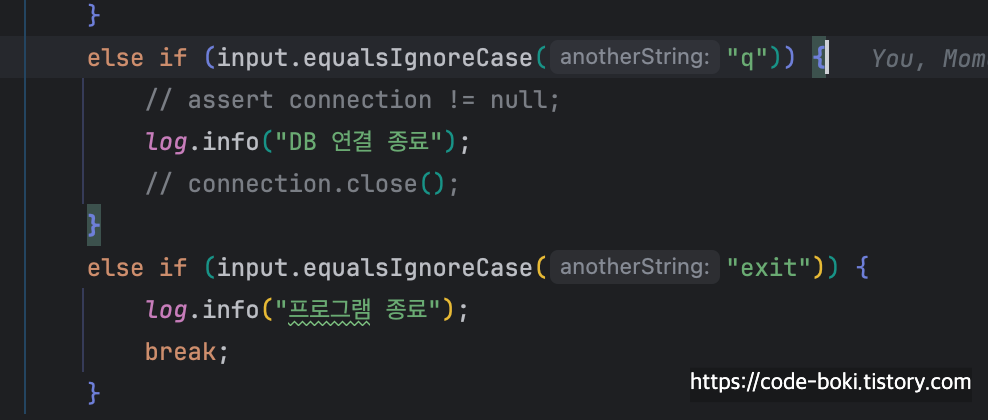
q를 입력해도 커넥션을 종료시키지 않고, exit에는 아무런 자원 정리 코드도 없다.

자바 프로세스를 6개정도 실행시켰다.
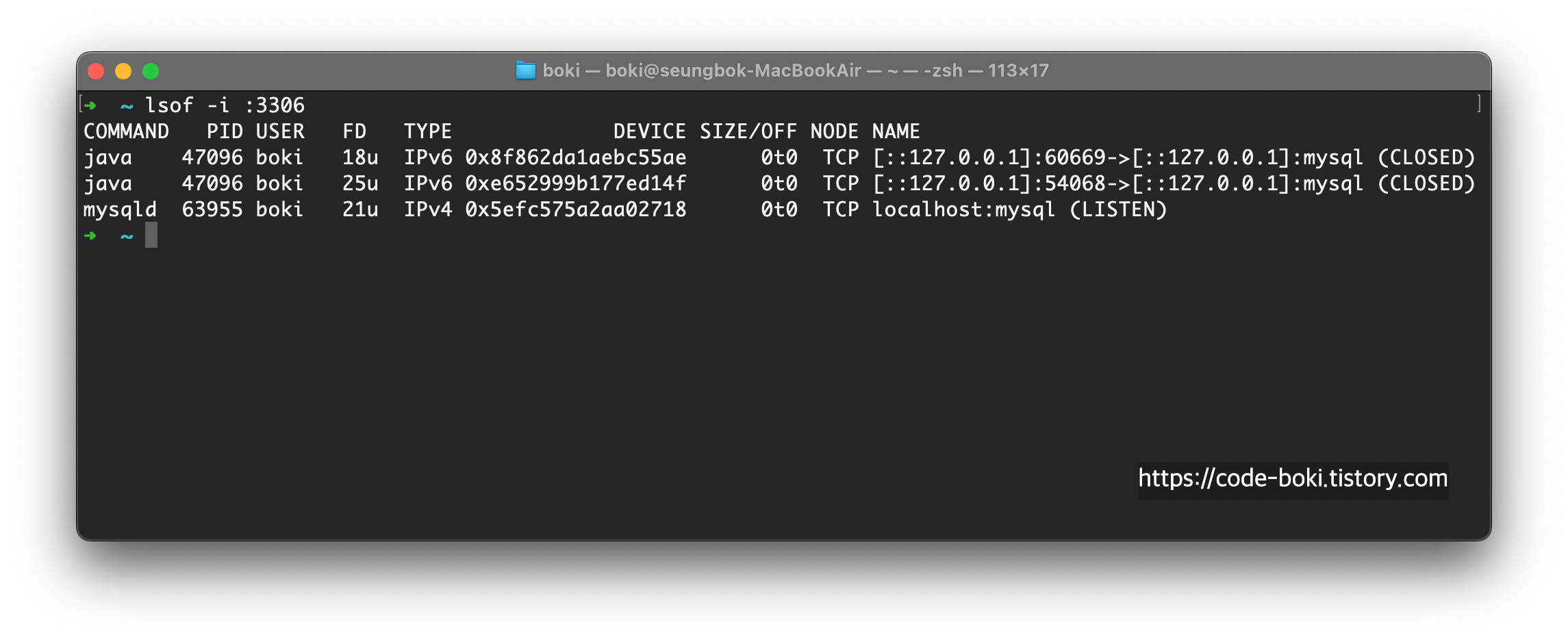
아직은 c를 입력해서 연결한게 1개도 없기 때문에 ESTABLISHED로 찍힌게 하나도 없다.

총 6개의 프로세스에서 c를 각각 입력해서 Connection을 맺어주도록 했다.
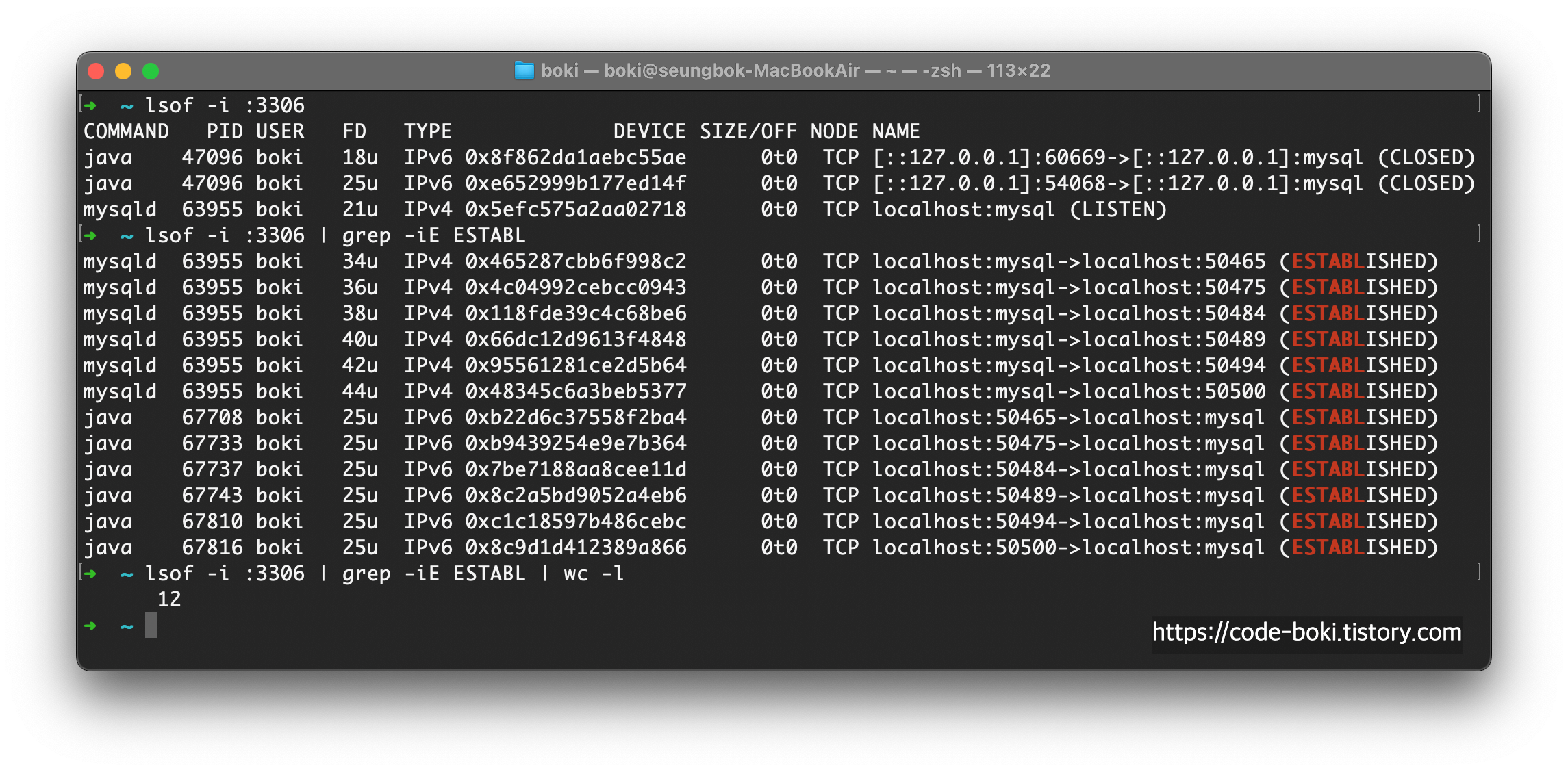
명령어 파이프라인, grep regex, word count를 사용해 갯수를 세어봤다.
mysqld<->java 각각 총 6쌍으로 TCP의 ESTABLISHED 상태가 12개로 나왔다.


어...? 커넥션을 종료하는 코드가 없으면 자원 누수가 계속 일어나는거 아닌가...!?라고 생각하셨나요~~
사실 단순한 Java Application이 안전하게!!(gracefully) 종료되기만 한다면, 자동으로 연결된 자원들을 정리해준다.
그럼 왜 여러 코드 예시에서는 try-with-resource나 finally를 사용하여 자원정리를 해주라고 하는 걸까?
그 이유로 몇가지 추측해볼 수 있는데,
첫번째로는 안전하지 않은 애플리케이션의 종료이다. 모종의 이유로 잘못 종료된 경우 사용하던 자원을 해제할 수 있도록 코드로 1차 방어를 해야 한다.
두번째로 아무리 단순한 애플리케이션이라도 내가 만든 것처럼 단순하지는 않다는 것이다. 그렇기때문에 첫 빠따에서 DB와 커넥션을 맺고, 다음 입력이 들어오는 n시간(초/분/시간...) 동안 DB와 관련되지도 않은 코드흐름이 있다면 쓸데없이 커넥션을 소비하고 있다는 점이다.
세번째는 두번째와 비슷한데, 자바나 코틀린으로는 주로 Web Server Application을 만든다. 웹 서버란 while(true)안에서 한정된 자원을 소비하고 반납하는 과정이 필요한데.. 이 과정에서 커넥션은 중요한 자원이기 때문이다. (추후에 언급: Connection Pool과 Connection cost)
그럼 코드를 안전하게 만들고, 마지막 4번째도 해결해보자.
@Slf4j
public class JdbcSimpleExample {
private static void cleanUpResources(Connection connection, Statement statement, ResultSet resultSet, Scanner scanner) throws SQLException {
if (connection != null)
connection.close();
if (statement != null)
statement.close();
if (resultSet != null)
resultSet.close();
if (scanner != null)
scanner.close();
log.info("DB 연결 종료 및 자원 해제");
}
public static void main(String[] args) throws SQLException, ClassNotFoundException {
Scanner scanner = new Scanner(System.in);
Connection connection = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
while (true) {
System.out.println("입력하세요: ");
System.out.println("c - DB 연결");
System.out.println("r - Query 실행");
System.out.println("q - DB 연결 종료");
System.out.println("종료하려면 'exit' 입력");
String input = scanner.nextLine();
if (input.equalsIgnoreCase("c")) {
Class.forName("com.mysql.cj.jdbc.Driver");
if (connection == null || connection.isClosed()) {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/rdb_study", "root", System.getProperty("dbPassword"));
log.info("DB 연결 성공");
} else {
log.warn("이미 DB 연결되어있음");
}
}
else if (input.equalsIgnoreCase("r")) {
if (connection == null || connection.isClosed()) {
log.warn("DB Connection 필요");
continue;
}
log.info("Query 실행");
final String query = "SELECT id, name, position, salary FROM employee";
pstmt = connection.prepareStatement(query);
rs = pstmt.executeQuery();
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
String position = rs.getString(3);
int salary = rs.getInt(4);
EmployeeResponse employee = new EmployeeResponse(id, name, position, salary);
log.info("employee: {}", employee);
}
}
else if (input.equalsIgnoreCase("q")) {
assert connection != null;
log.info("DB 연결 종료");
connection.close();
}
else if (input.equalsIgnoreCase("exit")) {
log.info("프로그램 종료");
cleanUpResources(connection, pstmt, rs, scanner);
break;
}
}
} finally {
cleanUpResources(connection, pstmt, rs, scanner);
}
}
}finally와 else if에 중복 코드가 있지만, 자원을 해제하는 건 중요한 목표이기때문에 이정도는 과하지 않다고 생각한다.
4개의 문제중 4개를 해결했다.
1. 접속정보 하드코딩&노출(특히 비밀번호)
2. 쿼리가 바로 인자로 전달되고 있어서 재사용이 어렵기 때문에 따로 문자로 추출해서 변수로 넘기기
3. 단순히 출력하는 과정밖에 없으므로, 응답객체를 만들어서 살짝 실제 애플리케이션과 비슷하게 출력하거나 로그로 찍어보기
4. 자원의 해제 과정이 없음
근데 그거 아는가....? 이게 바로 4개의 목표 중 첫번째였다ㅎㅎ
1. JDBC를 사용한 MySQL Connection Secure code & 수립 과정 살펴보기
2. Connection 비용
3. Spring/Springboot의 Connection Management
4. JPA(Hibernate)에서의 OSIV와 Connection과 상관관계
다음으로 왜 웹 서버를 개발할때, 특히 DB를 사용할때 Connection을 최소화해야 하는지 알아보자.
1. JDBC를 사용한 MySQL Connection Secure code & 수립 과정 살펴보기
2. Connection 비용
3. Spring/Springboot의 Connection Management
4. JPA(Hibernate)에서의 OSIV와 Connection과 상관관계
2번에 대한 내용은 하나도 없으면 서운할 공식문서에서 찾아봤다.

Insert 구문을 개선하려고 할 때, 들어가는 cost에 대한 비용이다.
영어에 약한 분들을 위해 한글로 보면...

일단 가장 중요한 부분은 Connecting: (3) 이다
사실 localhost에서 하는 테스트는 거의 의미가 없다. loopback으로 된 주소, 즉 같은 집에 있는 각각 다른 방으로 웹 서버와 db가 통신하는 것과 마찬가지다.
실제로는 AWS EC2(유럽 어느지역) <-> AWS RDS(서울 어느지역) 이라고 생각해보자.
traceroute로 확인해볼 수 있는 hop들도 많을 것이다. 그만큼 물리적인 거리가 생기고 수많은 네트워크 노드를 거치다보면 속도가 느려지고, 이것은 비용이 되는 것이다.
그렇기때문에 Web Server의 경우 이 Connection을 미리 n개 생성해서(HikariCP의 경우 기본값 10) 애플리케이션이 뜰 때 갖고 있는다.
비유하자면 서울에 사는 철수네와 파리에 사는 영희네가 통화를 주고받을 수 있는 길을 미리 뚫어서 10개정도 확보해놓은 것이다.
출처
https://dev.mysql.com/doc/refman/8.0/en/insert-optimization.html
MySQL :: MySQL 8.0 Reference Manual :: 10.2.5.1 Optimizing INSERT Statements
10.2.5.1 Optimizing INSERT Statements To optimize insert speed, combine many small operations into a single large operation. Ideally, you make a single connection, send the data for many new rows at once, and delay all index updates and consistency checki
dev.mysql.com
1. JDBC를 사용한 MySQL Connection Secure code & 수립 과정 살펴보기
2. Connection 비용
3. Spring/Springboot의 Connection Management
4. JPA(Hibernate)에서의 OSIV와 Connection과 상관관계
Spring Application을 열어서 확인해보자!
lsof는 network 명령어라 TCP, FD, PID, TYPE, NAME 등을 볼 수 있었고.... 이번에는 애플리케이션 내의 코드로 확인해보려고 한다.
간단하게 JPA를 사용해서 API 몇개 만들어봤다.
일단 정말 Connection을 10개 맺는지 스프링부트를 실행시켜서 lsof 명령어로 확인해보자.
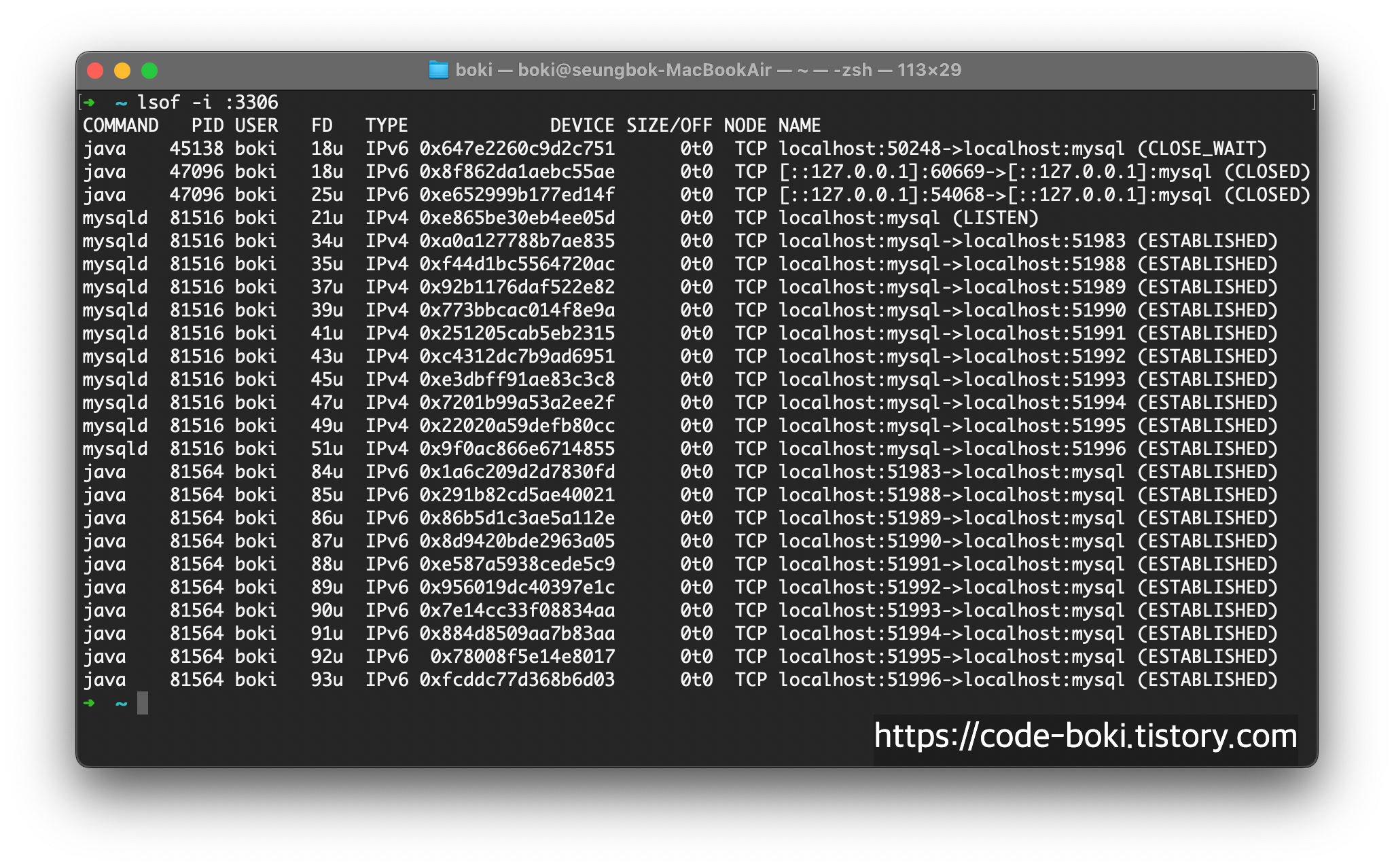
너무 많으니 wc로 세어보자..
총 20개. 즉 Mysql<->Spring이 총 10개의 Pair로 연결되었다.
이것은 HikariCP의 기본 Connection Pool 개수와 똑같다. 참고로 HikariCP의 CP가 Connection Pool의 약자이다.

HikariCPConfig.java에서도 확인이 가능하다.
기왕 알아보는 김에 요번에는 MySQL 명령어로도 확인해보자.
mysql> SHOW STATUS LIKE 'Threads_connected';
mysql> SHOW PROCESSLIST;위 두 명령어로 확인해볼 수 있다.
위 명령어는 스레드 개수를 확인하는 것이고, 아래는 프로세스 목록을 보는 것이다.
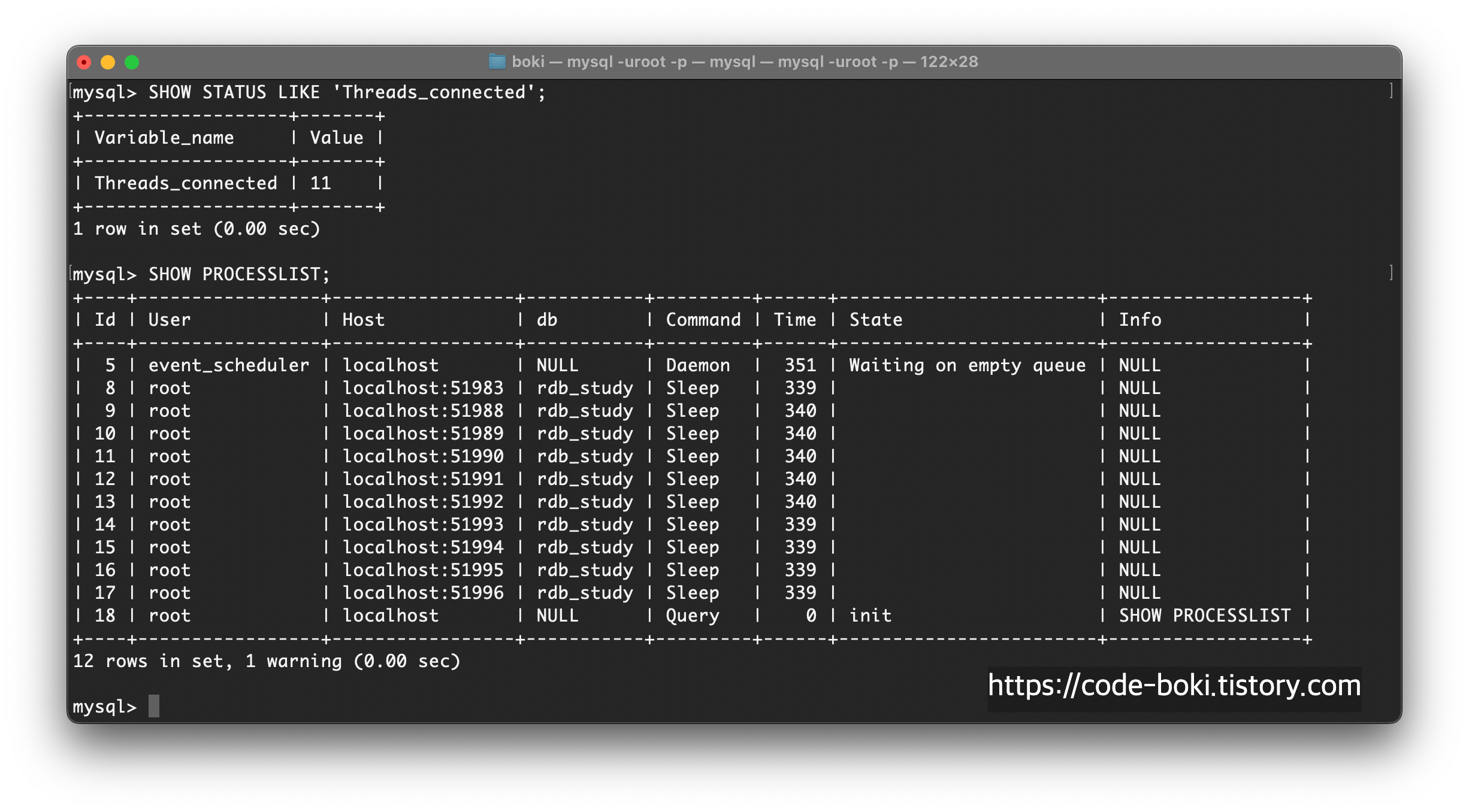
결과를 해석해보자~!
스레드의 개수는 11개, 프로세스 목록은 12개가 확인됐다.
별도의 프로세스마다 1개의 스레드가 1:1로 할당되고, MySQL에서 event를 처리하는 event_scheduler는 오직 1개의 프로세스만 데몬상태로 존재한다.
나머지 1개는 방금 실행된 쿼리가 실행되고 종료된 프로세스라고 하면, 총 10개의 프로세스, 즉 10개의 커넥션이 생긴 것이 맞다.
스레드 개수는 11개인데, event_scheduler를 위한 1개의 스레드와, 나머지 프로세스에 할당된 1개의 스레드가 맞다.
정확히 여러 커넥션을 깨워봐야 알겠지만, Sleep 상태일때는 프로세스1개에 기본 스레드1개로 시작되는 것 같다.
마지막으로 HikariCP의 정보를 출력하는 코드로도 확인해보자. 나중에 LazyConnectionDataSourceProxy에 대해서 다룰 예정이라서 코드를 추가했다.
import com.zaxxer.hikari.HikariDataSource;
import com.zaxxer.hikari.HikariPoolMXBean;
import lombok.extern.slf4j.Slf4j;
import org.springframework.jdbc.datasource.LazyConnectionDataSourceProxy;
import org.springframework.stereotype.Service;
import javax.sql.DataSource;
@Slf4j
@Service
public class ConnectionCheckService {
private final DataSource dataSource;
public ConnectionCheckService(DataSource dataSource) {
this.dataSource = dataSource;
}
public void printConnectionStatus() {
HikariPoolMXBean hikariPoolMXBean;
if (dataSource instanceof LazyConnectionDataSourceProxy) {
hikariPoolMXBean = ((HikariDataSource) ((LazyConnectionDataSourceProxy) dataSource).getTargetDataSource()).getHikariPoolMXBean();
} else {
hikariPoolMXBean = ((HikariDataSource) dataSource).getHikariPoolMXBean();
}
String border = "======================================";
String output = String.format("%n%s%nConnection Pool Status:%n" +
"Total Connections : %d%n" +
"Active Connections : %d%n" +
"Idle Connections : %d%n%s",
border,
hikariPoolMXBean.getTotalConnections(),
hikariPoolMXBean.getActiveConnections(),
hikariPoolMXBean.getIdleConnections(),
border);
log.info(output);
}
}그리고 Spring이 시작되는 이벤트를 받아서 시작하는 Runner에 이 서비스 코드를 실행시켰다.
import com.boki.springdbstudybok.service.ConnectionCheckService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.context.event.ApplicationReadyEvent;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class SpringInitializeRunner {
private final ConnectionCheckService connectionCheckService;
public SpringInitializeRunner(ConnectionCheckService connectionCheckService) {
this.connectionCheckService = connectionCheckService;
}
@EventListener
public void onApplicationEvent(ApplicationReadyEvent event) {
log.info("스프링 시작");
connectionCheckService.printConnectionStatus();
}
}
토탈 10개의 커넥션이 있고, 사용중인 커넥션은 0개, 사용가능한 커넥션은 10개인 것을 확인할 수 있다.
Network CLI, MySQL command, HikariCP Libaray, Code에서 확인해봤다.
실제로 운영할때는 프로메테우스, 그라파나, 엘라스틱서치, 데이터독, 핀포인트, Percona 등 이런 로그/메트릭을 수집한 결과를 시각화한 모니터링 툴을 사용한다. 저렇게 1회성으로 보는 일은 거의 없다.
운영상황에서의 컨트롤이 훨씬 중요한 것을 알지만..이 글에서는 Code level, Configuration에 대해서 알아보려고 한다.
취준생 혹은 주니어분들이 하는 실수가 DB를 얕게 공부하면서 연동하고, 잘 Wrapping된 라이브러리의 사용법만 익히려고 하는 것이다.
나 또한 그랬고.... MySQL 8.0 1/2권을 읽는다고 그것은 해결되지 않는다.
다음과 같은 것들에 관심이 있어야 한다. 기본 DB 설정값, 스프링이 먹는 설정값(상속되서 엎어치기되는 설정값) 등등...
그래서 요런 설정값들을 하나하나 살펴보면 좋다.
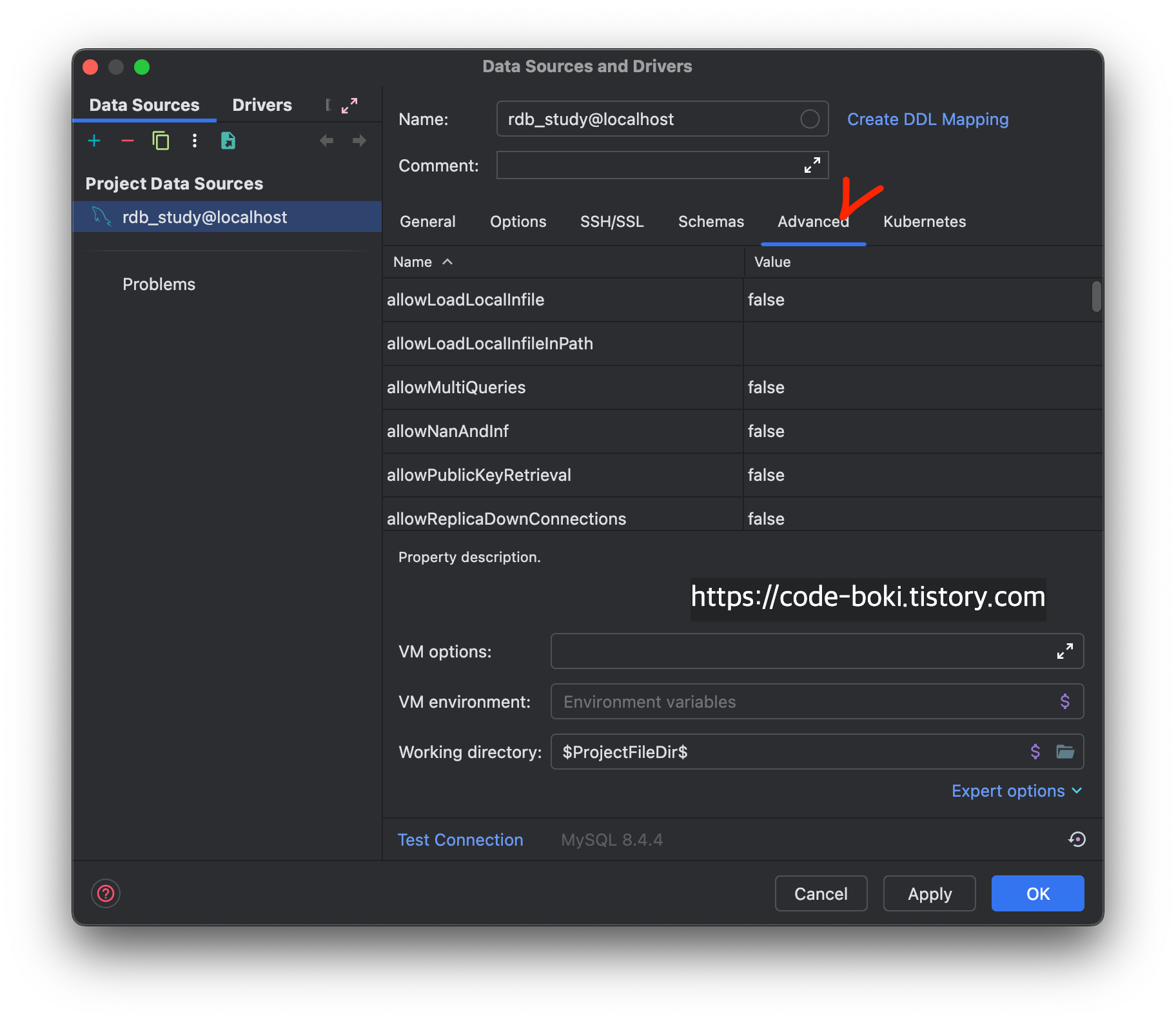
IntelliJ에서 확인할 수 있는 Advanced 탭. 고급이라고 하지만, Configuration이나 Properties로 이름을 바구고 General 다음으로 옮겨서 초보자들도 보게 해야 한다고 생각한다.
다음으로는 MySQL 명령어. mysqladmin이나 내부에서 확인할 수 있는 정보들
명령어
SHOW VARIABLES;
SHOW VARIABLES LIKE '%timeout%';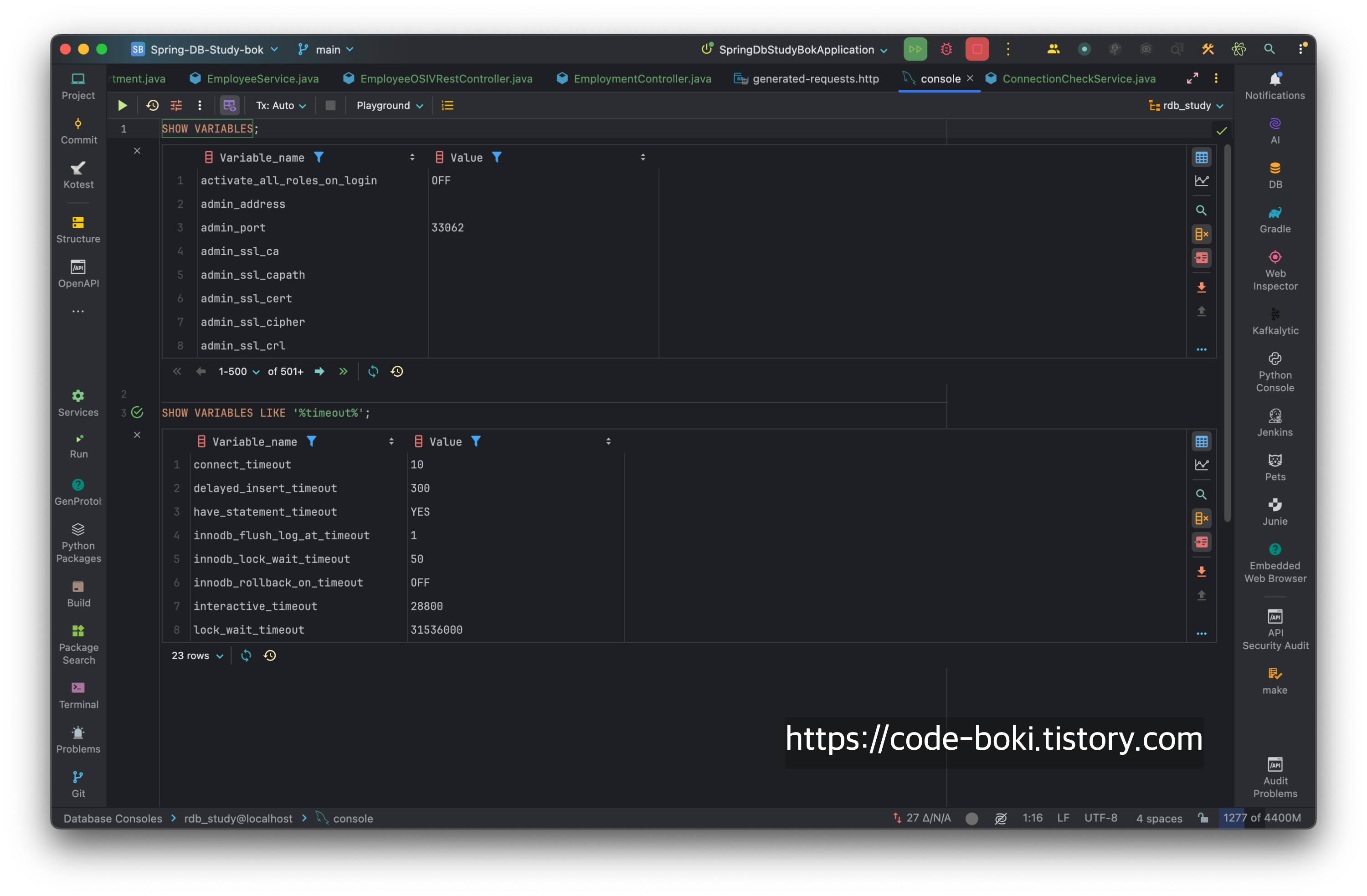
java 앱을 실행시키는 것에 그치지 않고 jps, jstat, jstack, jmap, jconsole 등을 알면 좋은 것처럼 mysql도 단순히 실행시키고 쿼리 개선하는 것에만 집중하지 않고 더 높은 수준으로 가려면 timeout(connection/read/lock), connection pool size 같은 개발 필수정보들과 엔진(myisam, innodb)에 대해서도 학습해야 한다.
- 출처
https://dev.mysql.com/doc/refman/8.0/en/mysqladmin.html
MySQL :: MySQL 8.0 Reference Manual :: 6.5.2 mysqladmin — A MySQL Server Administration Program
6.5.2 mysqladmin — A MySQL Server Administration Program mysqladmin is a client for performing administrative operations. You can use it to check the server's configuration and current status, to create and drop databases, and more. Invoke mysqladmin li
dev.mysql.com
그리고 Spring/Springboot 2.X버전 이상으로 개발중이라면 HikariCP에 대한 라이브러리도 살짝씩 살펴보면 좋다.
이어서 Spring Application을 좀 더 고도화시켜 나머지 3, 4번에 대해서도 알아보자.
1. JDBC를 사용한 MySQL Connection Secure code & 수립 과정 살펴보기
2. Connection 비용
3. Spring/Springboot의 Connection Management
4. JPA(Hibernate)에서의 OSIV와 Connection과 상관관계
3, 4번에 대해서 알아보기 위해서 이런 실험들을 할 것이다.
a. Non Transaction / Transaction / Read-Only Transaction에서의 Connection 차이
+ 트랜잭션이지만 실제 쿼리가 실행된 경우와 그렇지 않은 경우
b. 기본 DataSource인 HikariDataSource를 사용할때와, LazyConnectionDataSourceProxy을 사용할 때의 커넥션 차이
c. OSIV 옵션을 켰을 때와 껐을 때 Connection 차이
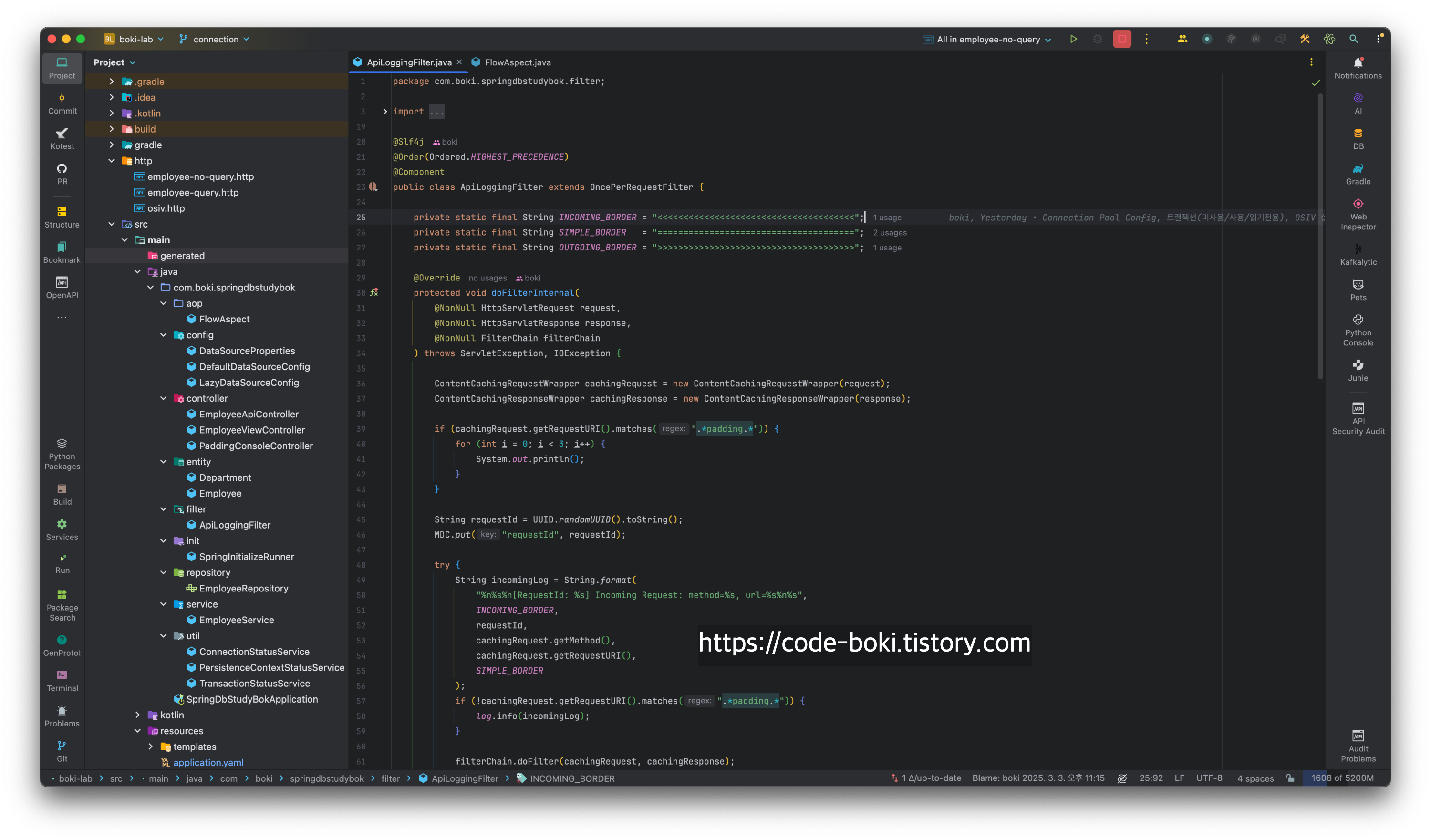
Tracing & Logging
- ApiLoggingFilter: MVC까지 진입하기 전 맨 처음 앞단 필터에서 어떤 요청이 들어오고 응답이 나갈지에 대한 로깅설정을 해줬다. 스트림에서 빼서 작업하는 건 없지만, 확장을 대비해 ContentCachingXXWrapper로 요청과 응답을 감싸고, 멀티스레드 환경에서도 Tracing이 가능케 하기 위해 MDC에 요청ID를 UUID로 만들어 넣어줬다. 이로써 톰캣 스레드풀에 반납하기 전까지 들어오는 하나의 흐름은 같은 requestId를 가진다. 추가로 요청에서는 method, api path.. 응답에서는 상태 코드가 나오도록 하고, padding이라는 api가 들어오면 로깅을 찍지 않도록 했다. 당연히 스레드풀에 반납하기 전에 MDB는 비워줘야 하기때문에 clear()는 꼭 호출해야 한다.
- FlowAspect: DB Connection, Transaction, PersistenceContext에 대한 상태를 공통적으로 출력하기 위해 AOP로 뺐다. 컨트롤러와 서비스 각각 다른 포인트컷을 만들고, 서비스에서만 해당 상태지표들을 로직이 실행되고 난 다음 로그로 출력되게 했다.
Configuration
- DataSourceProperties: DB접속정보로 만들어지는 정보들을 @ConfigurationProperties를 사용해 객체로 재사용이 가능하도록 했다. Setter만 사용하지 않으면 되기때문에 간편하게 @Data 어노테이션을 사용했다.
- DefaultDataSourceConfig: HikariConfig객체를 만들어서 최종적으로 new HikariDataSource(config)를 반환하며 DataSource 빈으로 등록했다.
- LazyDataSourceConfig: 위에서 만들어진 HikariDataSource를 한번 더 new LazyConnectionDataSourceProxy로 감싼 DataSource를 빈으로 등록했다.
Util
- ConnectionStatusService: HikariCP의 정보(전체 / 사용 / 가용 커넥션 개수)를 로그로 출력하는 유틸 서비스.
- PersistenceContextStatusService: 영속성 컨텍스트의 상태(EntityManager가 open된 상태, Flush Mode, Binding 여부)를 로그로 출력하는 유틸 서비스.
- TransactionStatusService: 트랜잭션 Active 상태, Read-Only 상태, 이름, 고립 레벨 등을 로그로 출력하는 유틸 서비스.
Core Service
package com.boki.springdbstudybok.service;
import com.boki.springdbstudybok.entity.Department;
import com.boki.springdbstudybok.entity.Employee;
import com.boki.springdbstudybok.repository.EmployeeRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.time.LocalDateTime;
import java.util.List;
@Slf4j
@RequiredArgsConstructor
@Service
public class EmployeeService {
private final EmployeeRepository employeeRepository;
private final Department department = new Department();
private final List<Employee> mockEmployees = List.of(
new Employee(2L, "lee", 25, "Frontend", 2000, LocalDateTime.now(), null, null, department),
new Employee(1L, "kim", 30, "Backend", 3000, LocalDateTime.now(), null, null, department)
);
/**
* Query를 요청하지 않는 메서드 모음
*/
public List<Employee> findEmployeesWithoutTx() {
return mockEmployees;
}
@Transactional
public List<Employee> findEmployeesWithTx() {
return mockEmployees;
}
@Transactional(readOnly = true)
public List<Employee> findEmployeesWithReadOnlyTx() {
return mockEmployees;
}
/**
* 실제 Query를 요청하는 메서드 모음
*/
public List<Employee> findEmployeesWithoutTx2() {
return employeeRepository.findAll();
}
@Transactional
public List<Employee> findEmployeesWithTx2() {
return employeeRepository.findAll();
}
@Transactional(readOnly = true)
public List<Employee> findEmployeesWithReadOnlyTx2() {
return employeeRepository.findAll();
}
}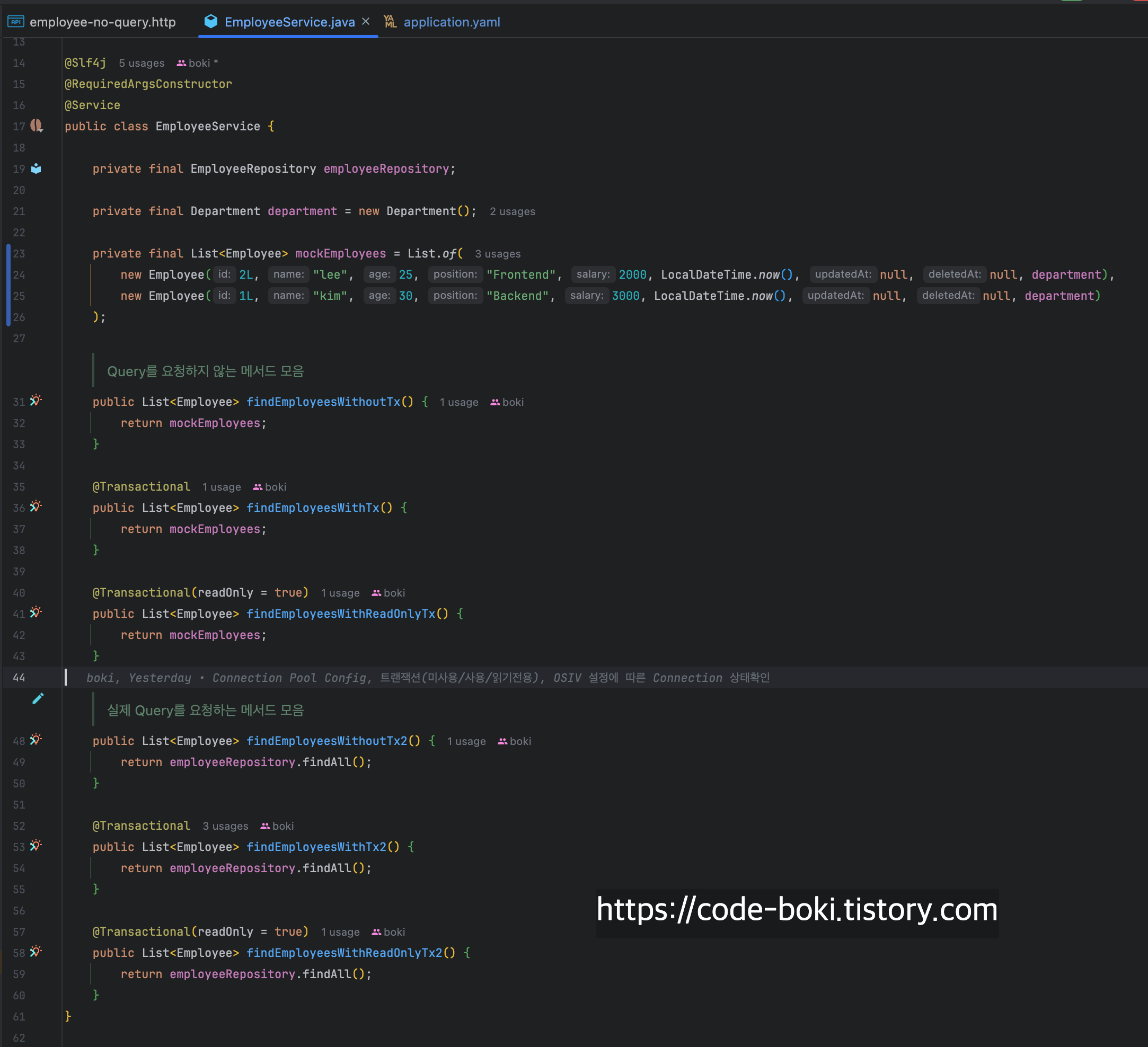
- EmployeeService: 임시로 만들어진 객체를 반환하는 메서드들, 실제 Persistence Layer를 사용하여 쿼리가 나가는 메서드들로 크게 나눌 수 있고, 트랜잭션을 붙이지 않은 메서드, 트랜잭션을 붙인 메서드, 읽기전용 트랜잭션 3개로 분리. DTO는 일부러 만들지 않았음.
Controller
- EmployeeApiController: 완전 RESTful하지는 않지만.. REST Api Controller. OSIV를 테스트하기 위해 Proxy객체를 초기화하는 코드가 있는 api, 추가로 Core Service에 있는 메서드들을 각각 실행하는 api들을 분리해놓음. 굳이 파라미터를 넘겨 if나 switch로 분기를 타는것보다는 명확한 api가 낫다고 생각해 여러개 만듦(/no-query/no-tx, /no-query/tx, /no-query/read-tx, /query/no-tx, /query/tx, /query/read-tx).
- EmployeeViewController: OSIV를 테스트하기 위해 타임리프 의존성을 추가하고, html까지 객체가 넘어가는지 보기 위해 추가한 View Controller. Model 인자에 데이터를 담아서 html로 넘김. ViewResolver가 작동함.
- PaddingController: 여러 API를 호출하고 눈에 보기 좋게 터미널에 빈 로그를 출력하기 위한 아무 의미 없는 api 컨트롤러
Test
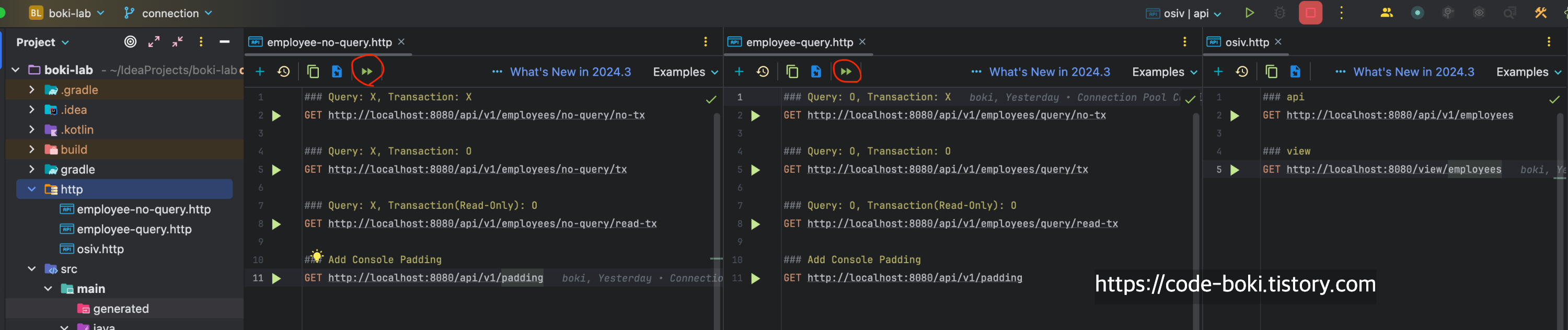
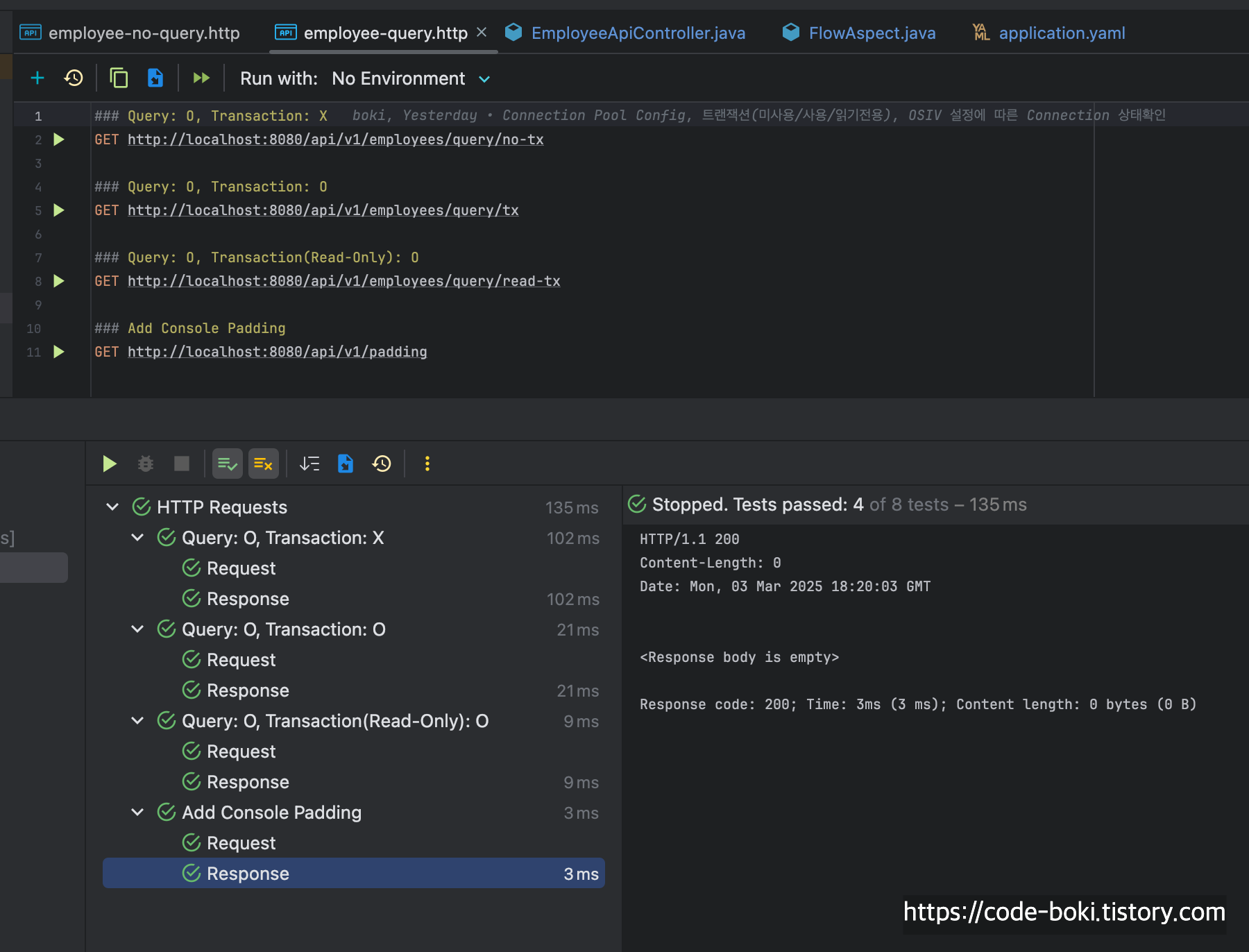
테스트는 테스트코드를 굳이 작성하지 않고, intelliJ에 내장된 http-request로 수행.
no-query api / query api / osiv api 파일 3개로 분리하여 연구하기 쉽게 분리. Play버튼을 겹쳐놓은 듯한 버튼을 클릭하면 맨 위에 적힌 순서대로 api 테스트가 모두 실행된다.
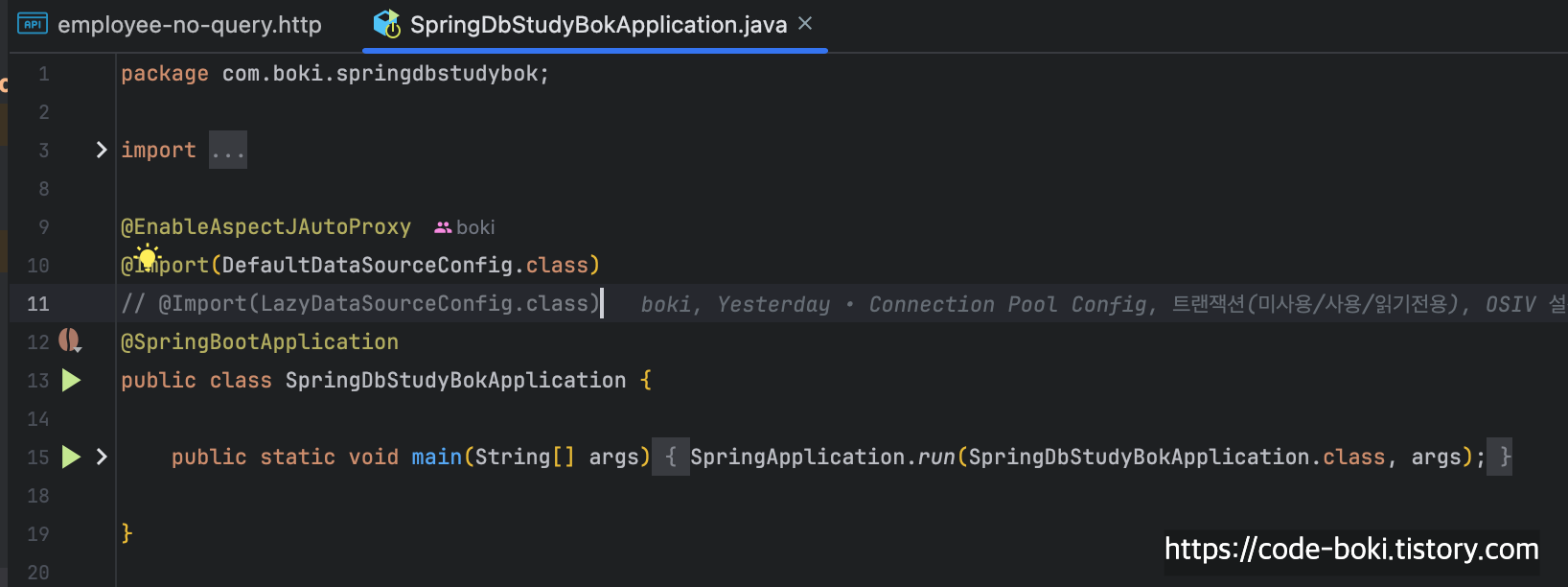
2개의 Configuration을 만들고 Import를 사용해 각각 다른 Datasource가 빈으로 등록되도록 했다.
이제 준비된 테스트를 실행해보자(+아직 osiv 옵션은 기본값인 true)
- HikariDataSource + Mock객체를 반환하는 no-query API
a. 트랜잭션 X
b. 트랜잭션 O
c. 트랜잭션 Read-Only
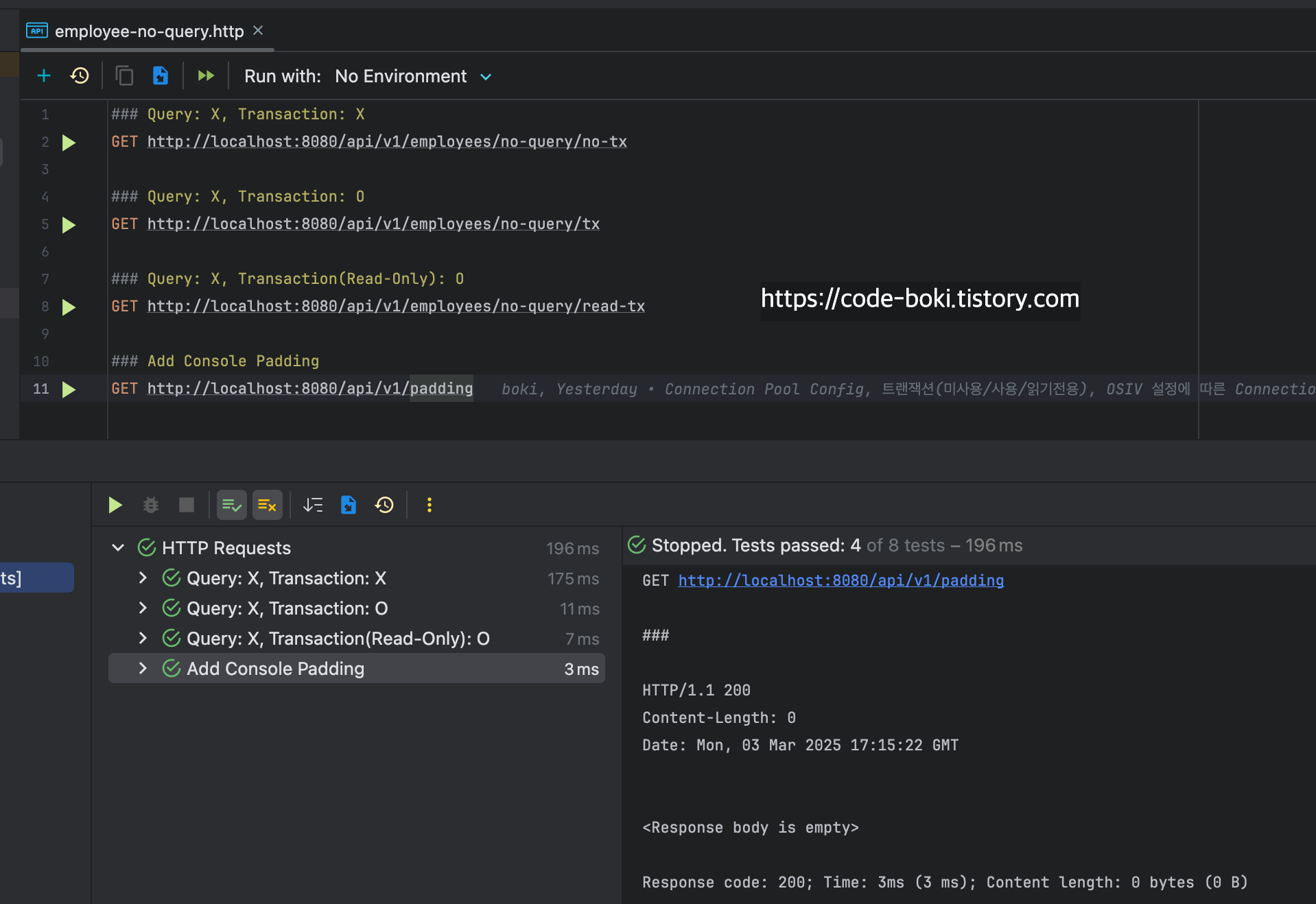
기본 Datasource가 적용되었는지 확인하는 println을 Config 클래스에 하나 껴놨다ㅋ.

스프링이 뜨고 난 다음의 이벤트를 받아서 커넥션 풀 정보를 한번 출력해봤다.
이후에 <<<<<<<<<<의 부분을 보면 LoggingFilter에서 정보를 잘 받아서 출력한 모습을 볼 수 있다.
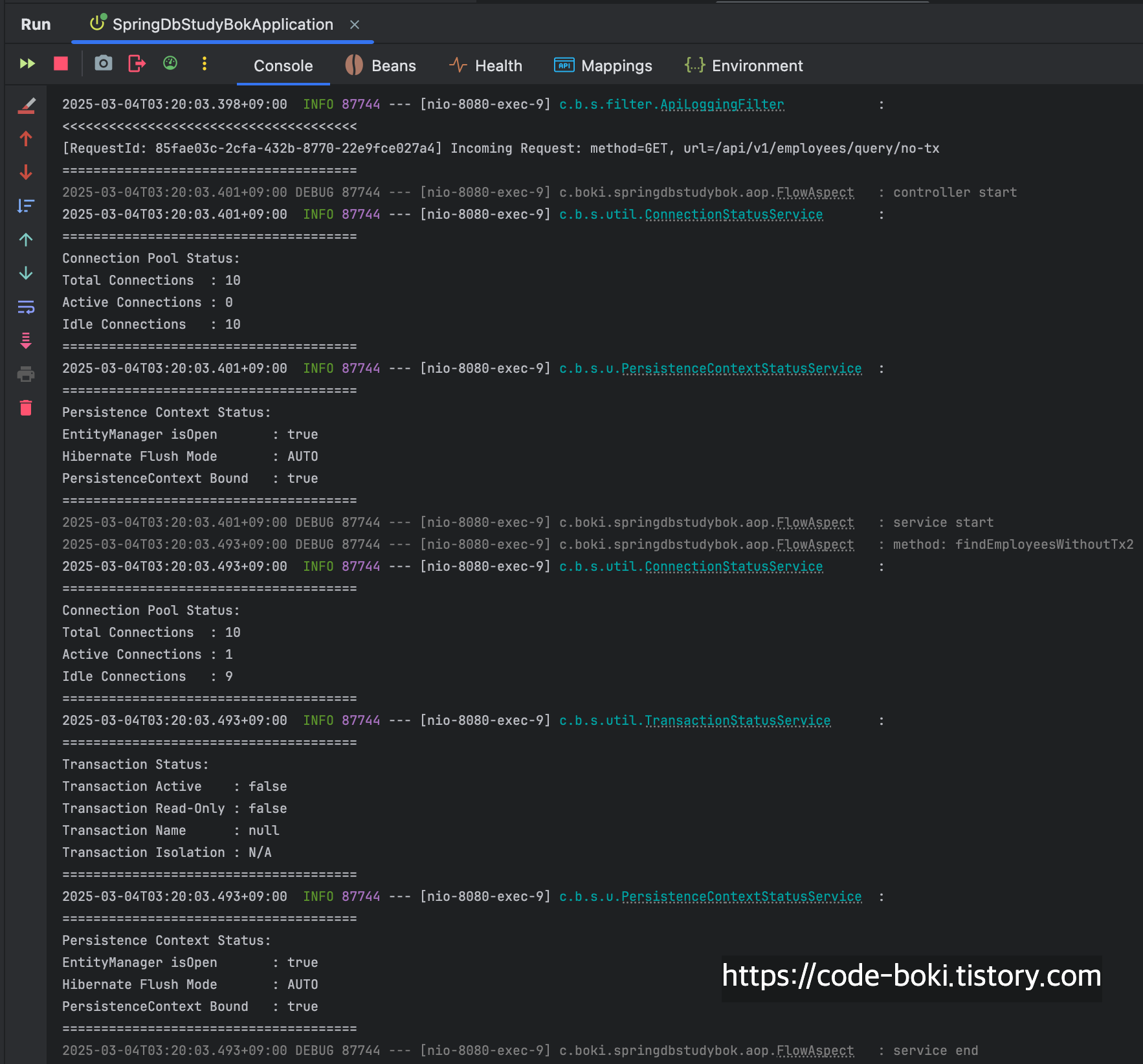
> [ 분석 시작: /no-query/no-tx ]
그 다음으로 AOP에서 controller / service의 진입, 탈출을 debug 메시지로 찍었다.
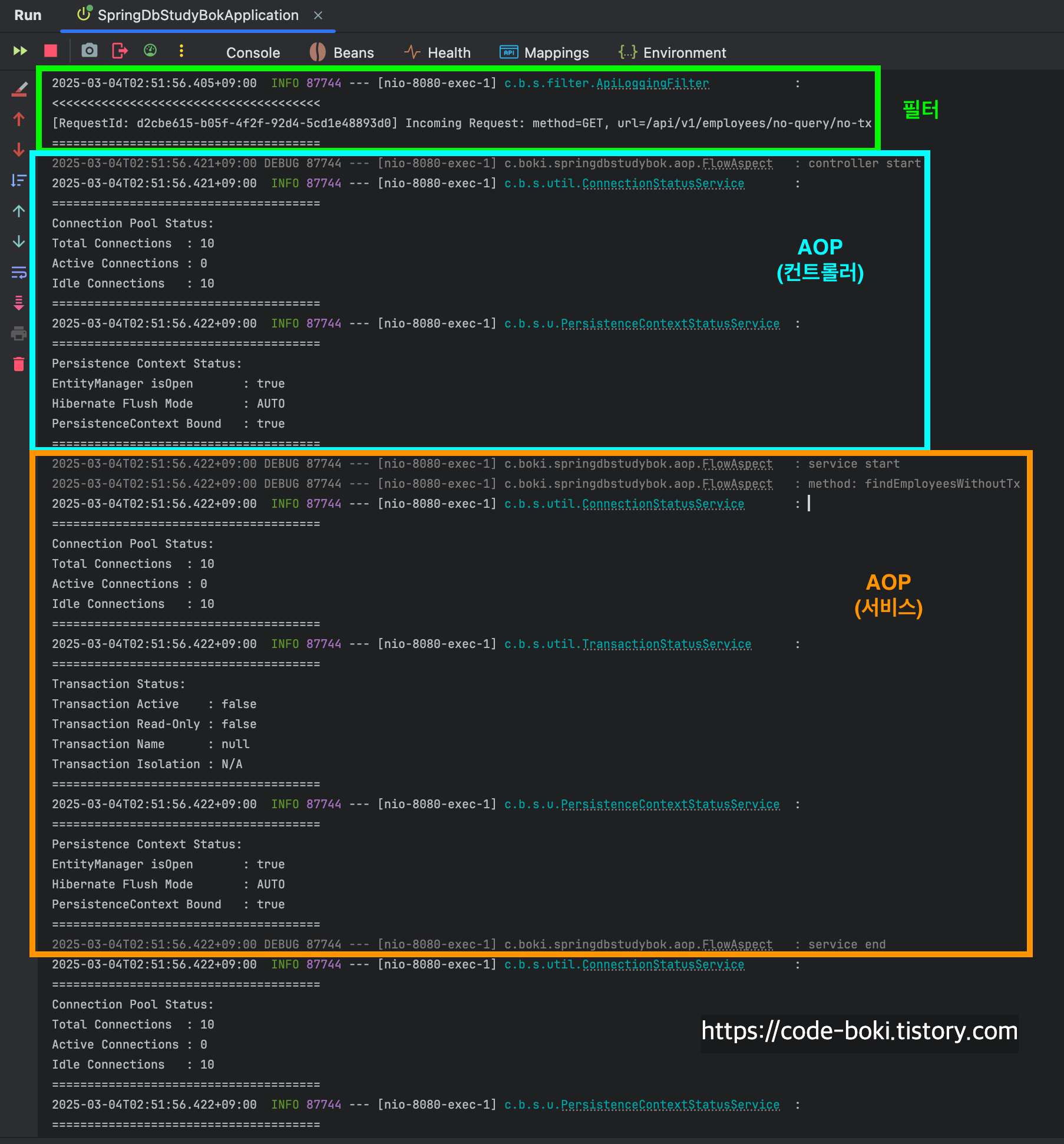

서비스 내에서는 info 레벨로 커넥션 정보, 트랜잭션 정보, 영속성컨텍스트 정보가 출력되도록 했다.
컨트롤러 진입&반환시점 전에 커넥션/영속성 컨텍스트 로그를 출력했다.
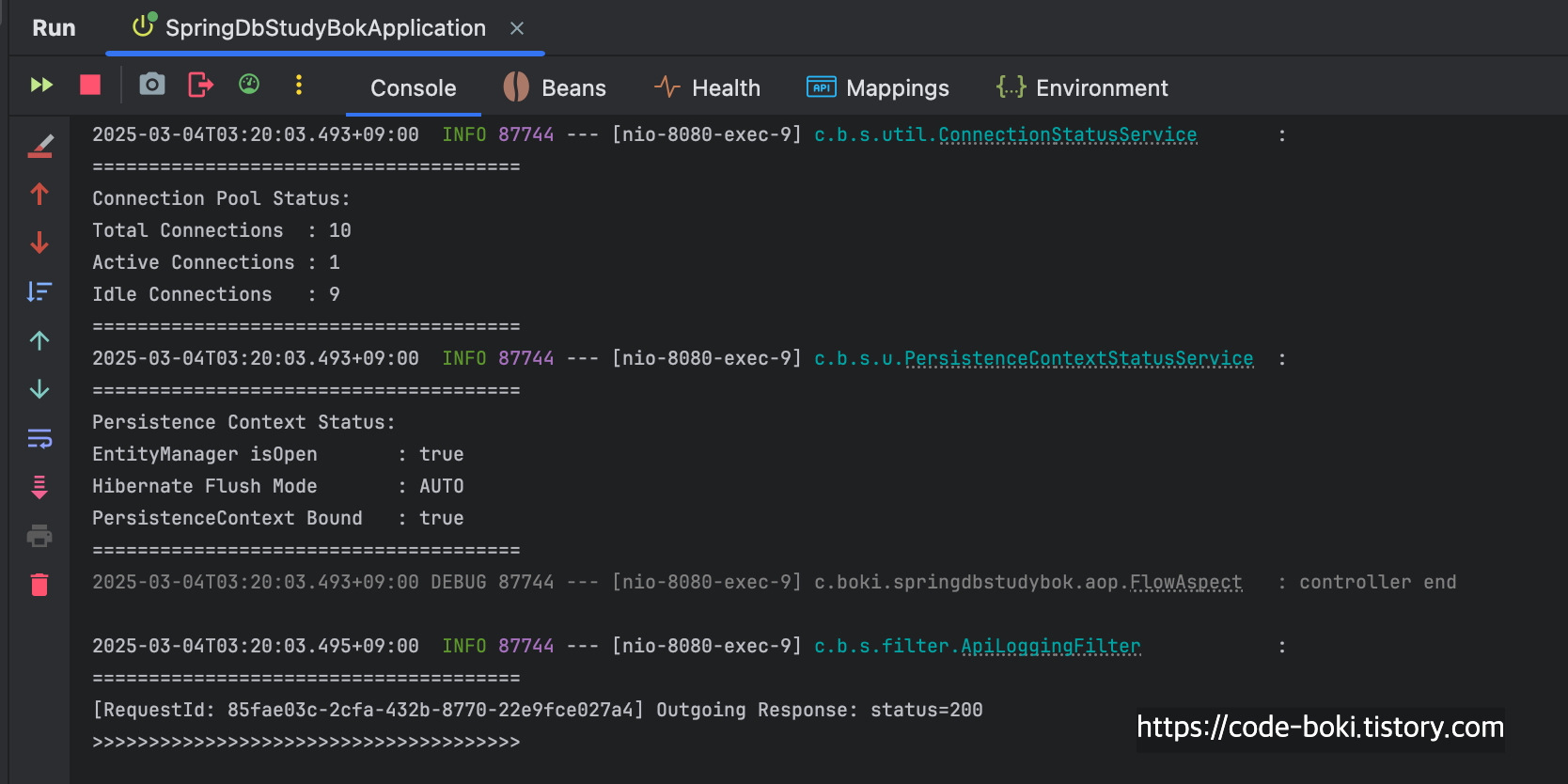
이제 분석해보자...... 트랜잭션이 없고, mock객체를 반환하는 API는 당.연.하게도 DB 커넥션을 1개도 사용하지 않았고(10개 유지), 트랜잭션도 활성화되지 않았으며, Flush Mode도 AUTO인 것을 알 수 있다.
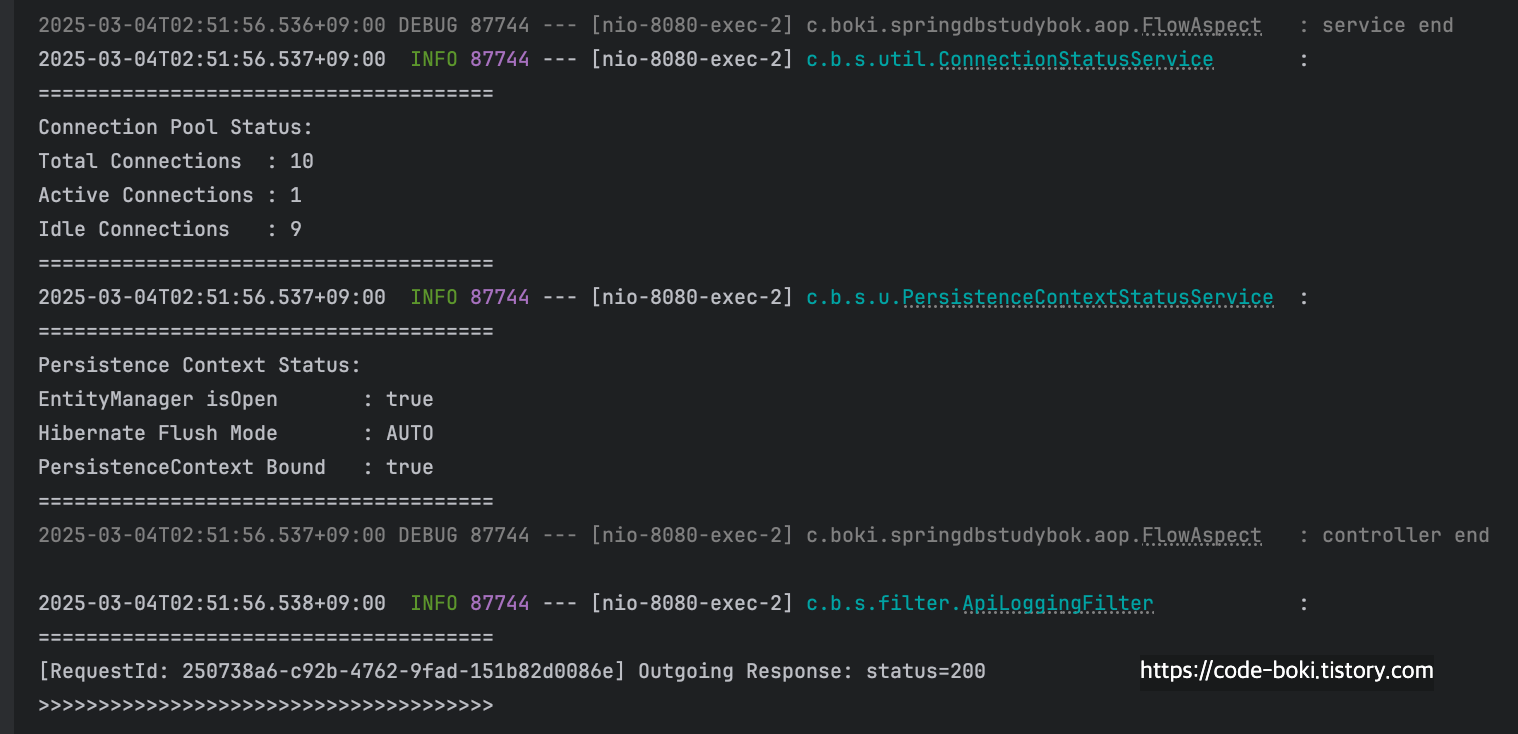
최종적으로 controller end 이후에 LoggingFilter에서 응답 로그를 >>>>>>>>>> 와 함께 출력한 것을 볼 수 있다.
필터 -> 컨트롤러 -> 서비스 -> 컨트롤러 -> 필터까지의 흐름을 로그를 통해 볼 수 있었다.
[ DB Conn: X(서비스/컨트롤러), Trasaction: X, Read-Only: X, Flush: Auto(서비스/컨트롤러), Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /no-query/no-tx ]
> [ 분석 시작: /no-query/tx ]
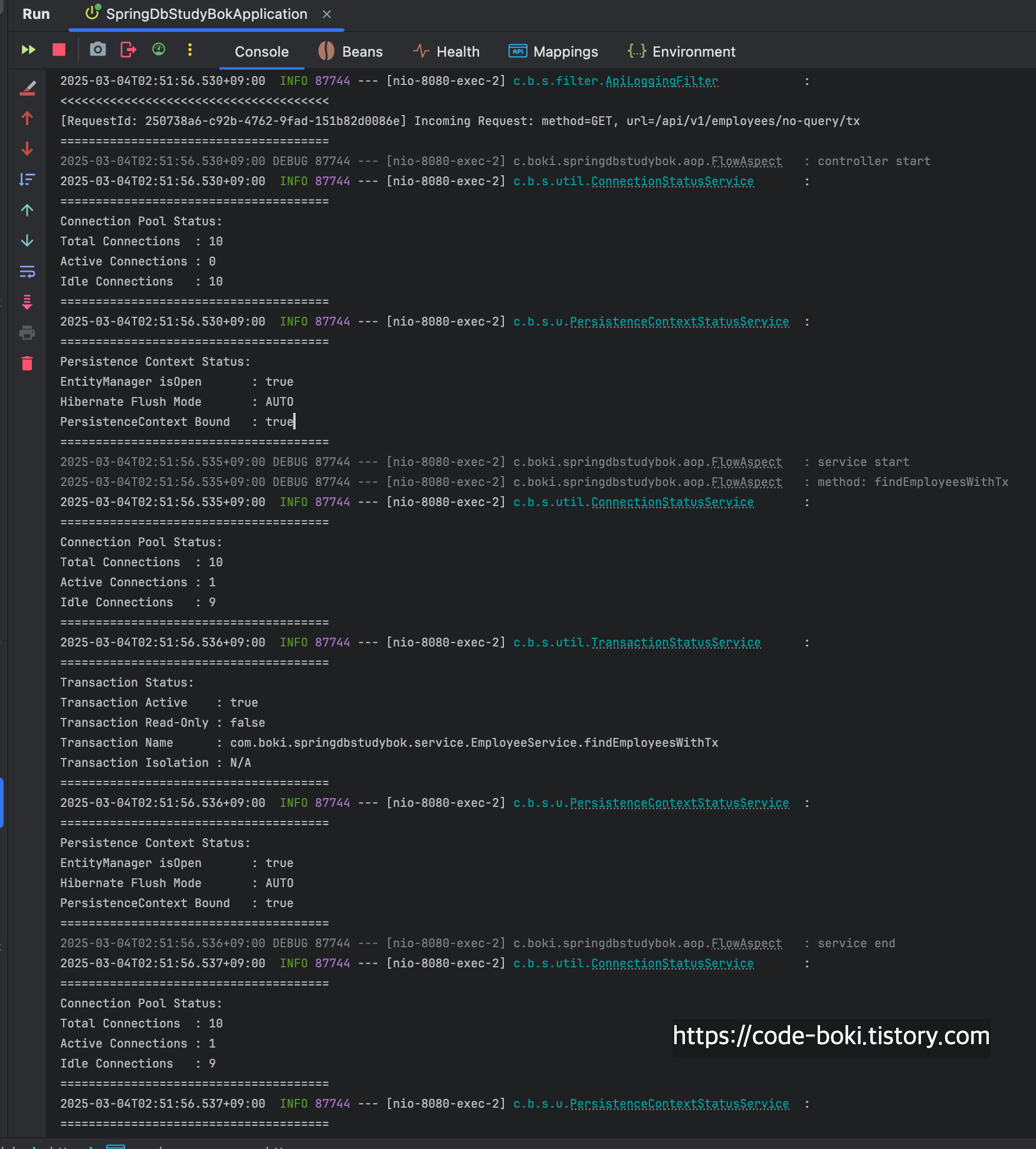
아까와는 다른 점이 있다!
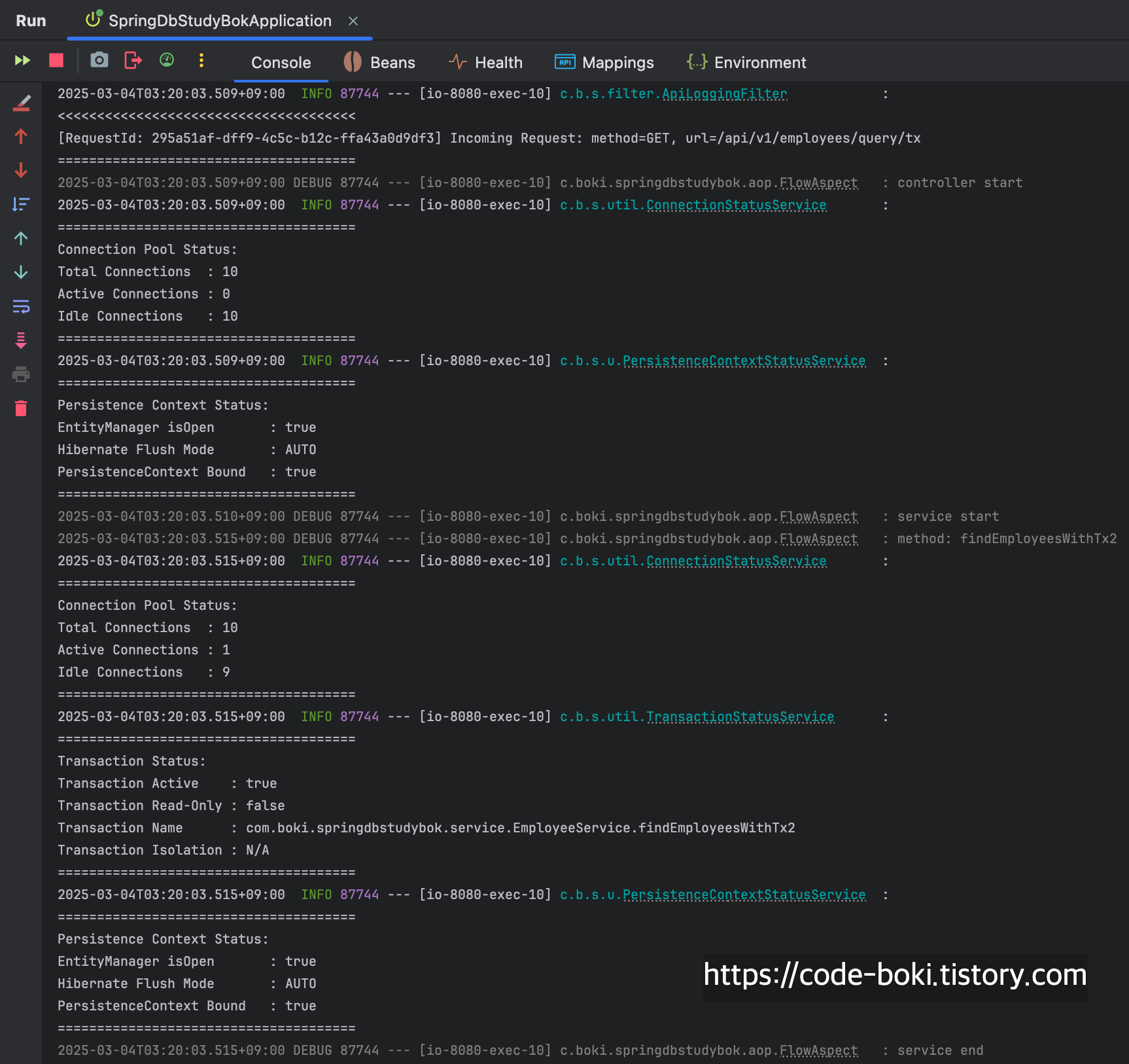
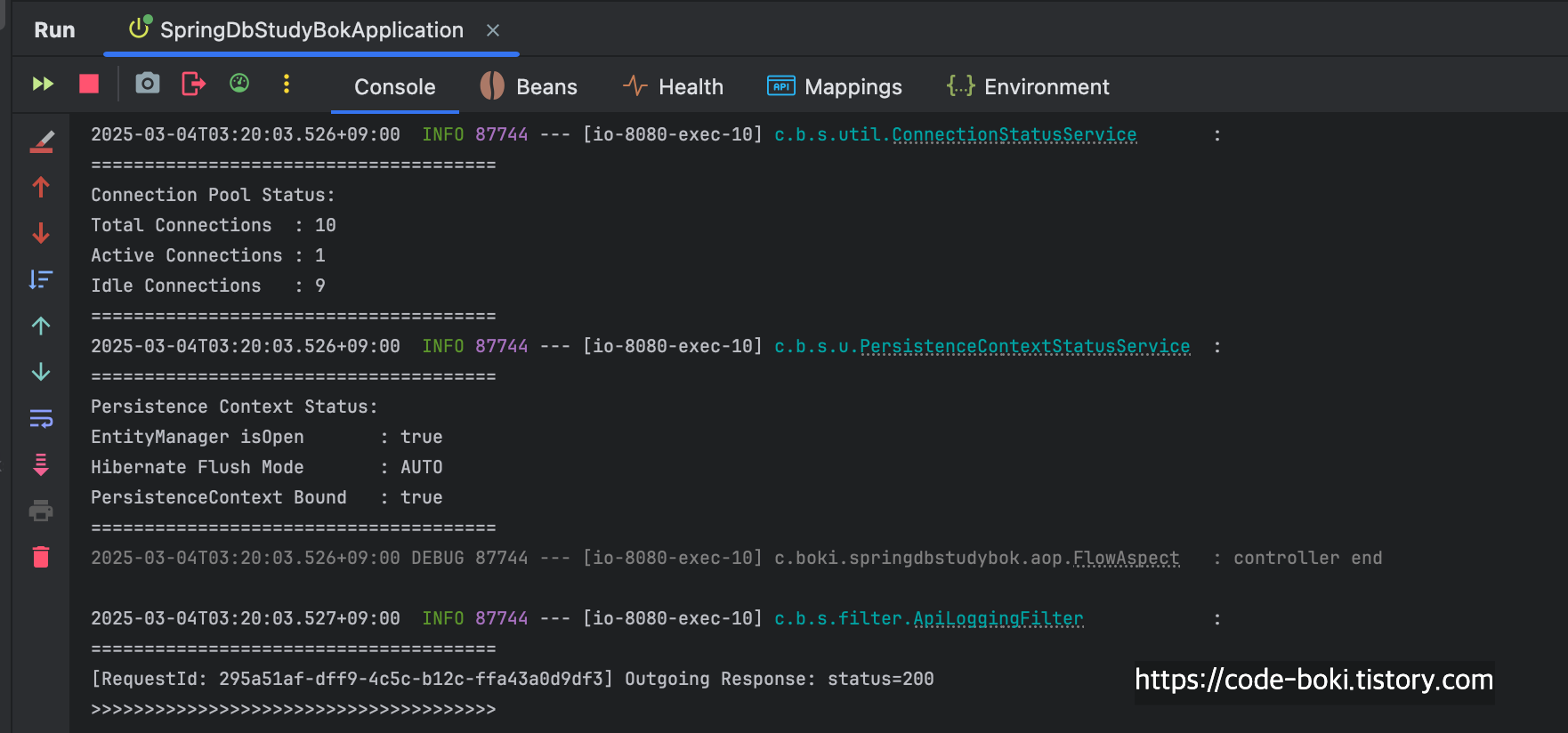
@Transactional 하나 붙였을 뿐인데, Mock객체를 반환하는데도 불구하고 커넥션을 1개 소모하고 있다.
당연히 AOP Proxy에 의해 동작하기 때문에 서비스의 메서드 내부에서는 트랜잭션도 활성화가 된 상태이다.
컨트롤러가 끝나기 직전까지도 커넥션이 살아있는 모습을 볼 수 있었다.
[ DB Conn: O(서비스/컨트롤러), Trasaction: O, Read-Only: X, Flush: Auto(서비스/컨트롤러), Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /no-query/tx ]
> [ 분석 시작: /no-query/read-tx ]


이번에도 여전히 커넥션을 1개 물고 있다. 대신 달라진 점은 Read-Only 트랜잭션이기때문에 Read-Only 트랜잭션이 활성화되었고, 그에 따라 서비스 레이어의 메서드 내에서 Flush Mode가 AUTO가 아닌 MANUAL이 된다. 컨트롤러쪽으로 오면 여전히 커넥션이 살아있고, Flush Mode는 AUTO로 돌아오고, Bound도 true이다.
[ DB Conn: O(서비스/컨트롤러), Trasaction: O, Read-Only: O, Flush: Manual/Auto, Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /no-query/read-tx ]
어느정도 흥미로운 정보들을 얻을 수 있었다. 이번에는 Mock Response가 아닌 실제 쿼리가 나가는 api들에 대해서 테스트해보자.
- HikariDataSource + 실제 DB 정보를 반환하는 query API
a. 트랜잭션 X
b. 트랜잭션 O
c. 트랜잭션 Read-Only
> [ 분석 시작: /query/no-tx ]
SQL 로깅을 활성화시키진 않았지만, 전부 다 repository를 사용하는 메서드를 호출한다.
그 결과로 @Transactional이 붙지 않은 메서드였는데도 DB 커넥션을 쓰고 있는 것을 볼 수 있다.
이전 Mock 결과를 반환하는 메서드는 커넥션을 쓰고 있지 않았는데, 실제로 DB 쿼리가 호출이 필요한 경우에 커넥션을 가져다 쓴다.
하지만, 트랜잭션이 활성화되지는 않은 상태다.
서비스 호출이 끝난 뒤, 컨트롤러단까지 커넥션이 살아 있는 모습을 볼 수 있다.
[ DB Conn: O(서비스/컨트롤러), Trasaction: X, Read-Only: X, Flush: Auto(서비스/컨트롤러), Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /query/no-tx ]
> [ 분석 시작: /query/tx ]
선언적이자 수동 트랜잭션을 활성화시켰다는 점 빼고는 위와 모두 동일하다.
[ DB Conn: O(서비스/컨트롤러), Trasaction: O, Read-Only: X, Flush: Auto(서비스/컨트롤러), Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /query/tx ]
> [ 분석 시작: /query/read-tx ]
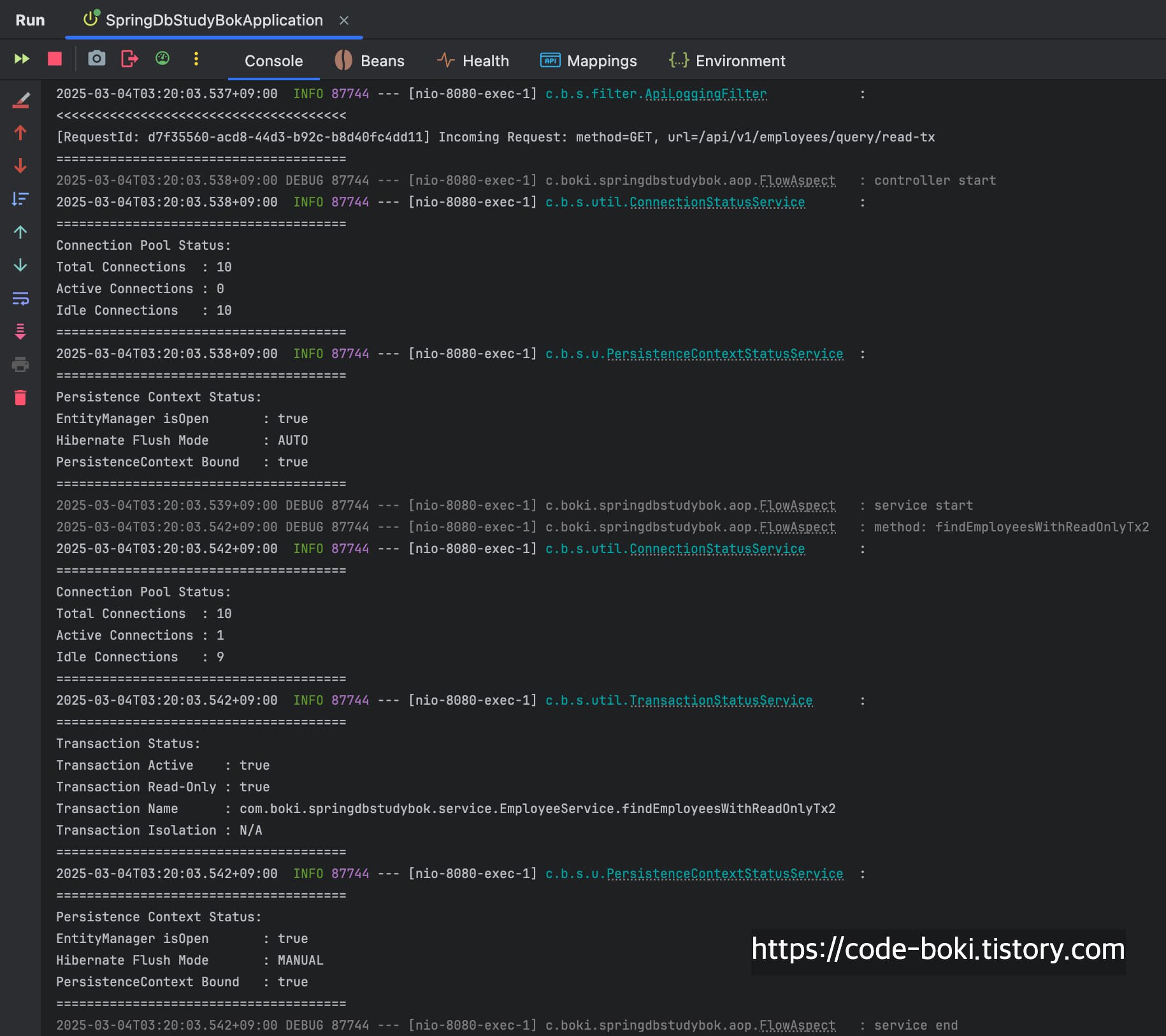
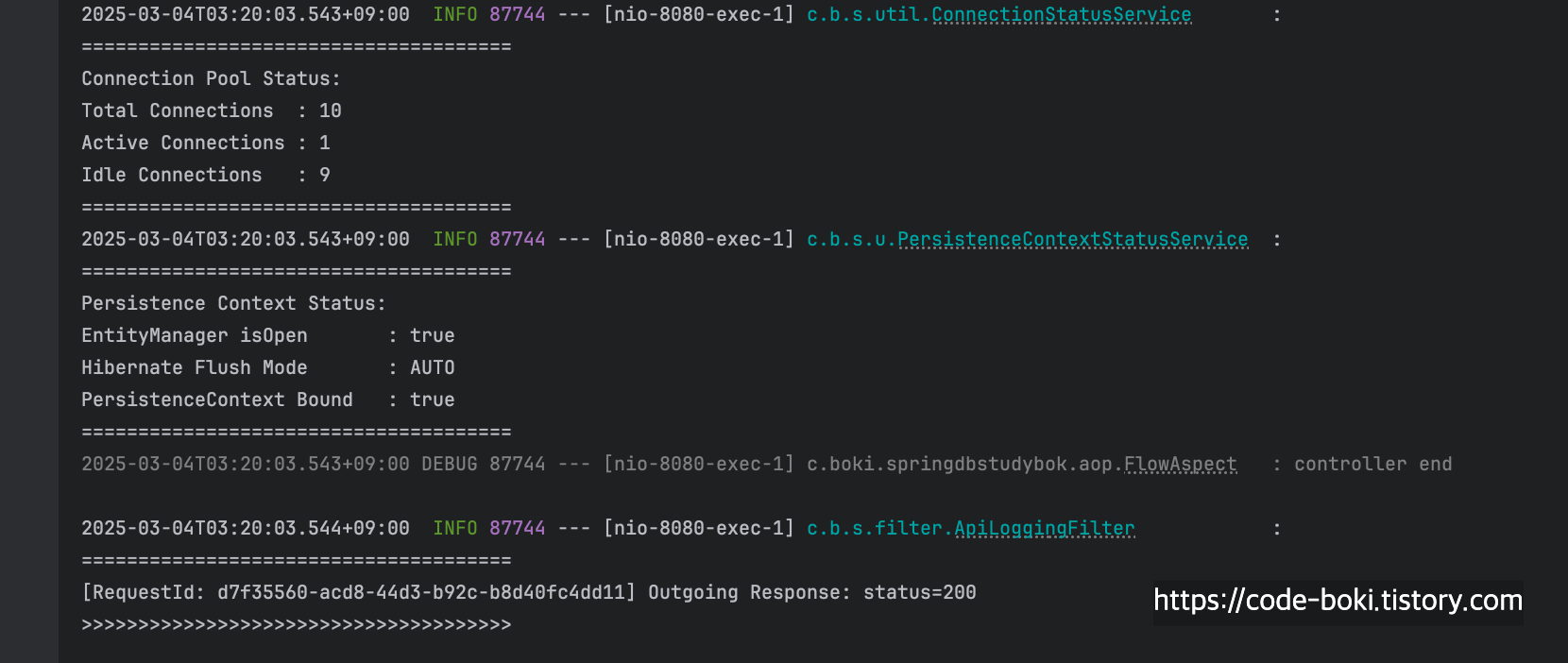
실제 조회쿼리가 발생했고, Read-Only 트랜잭션이 활성화되어 있기때문에 서비스 레이어에서만 Flush Mode가 MANUAL이 되며, 다시 서비스 로직이 끝난 컨트롤러로 오면 커넥션은 살아있고 Flush Mode가 AUTO로 되는 것을 알 수 있다.
[ DB Conn: O(서비스/컨트롤러), Trasaction: O, Read-Only: O, Flush: Manual/Auto, Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /query/read-tx ]
이번에는 LazyConnectionDataSourceProxy로 테스트해보자!!
@Import를 바꿔서 스프링 애플리케이션을 재시작해줬다.
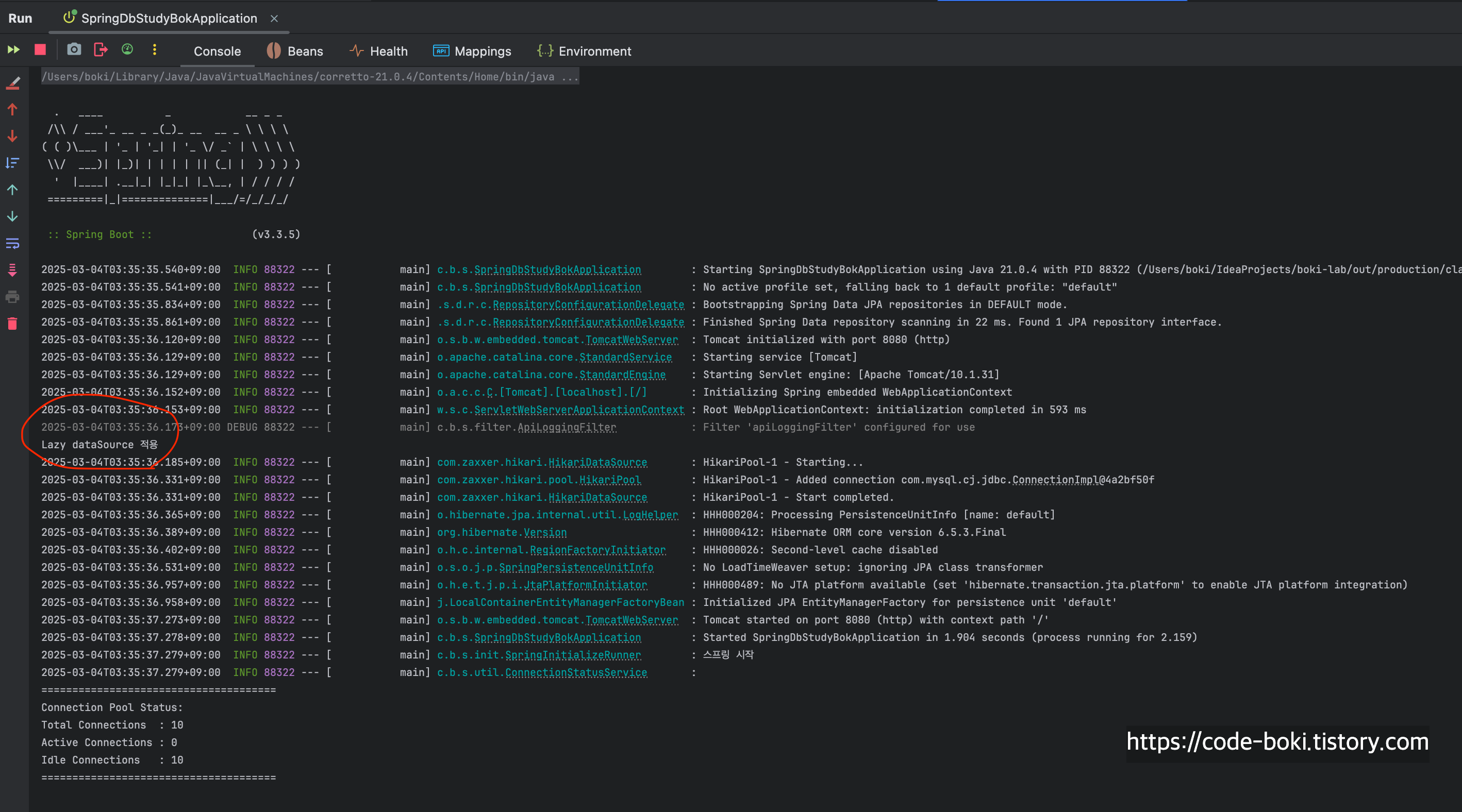
- LazyConnectionDataSourceProxy + Mock객체를 반환하는 no-query API
a. 트랜잭션 X
b. 트랜잭션 O
c. 트랜잭션 Read-Only
> [ 분석 시작: /no-query/no-tx ]
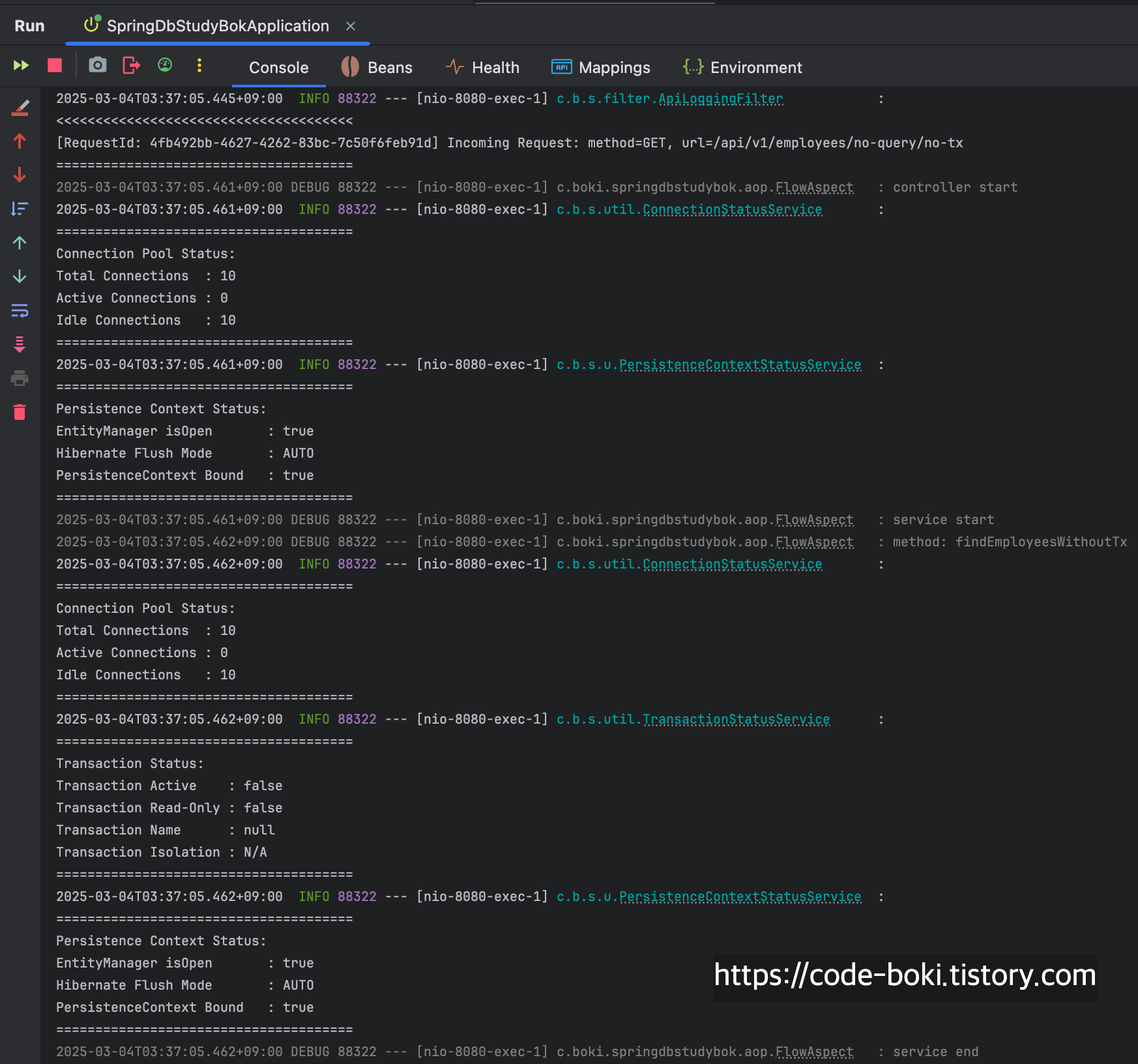
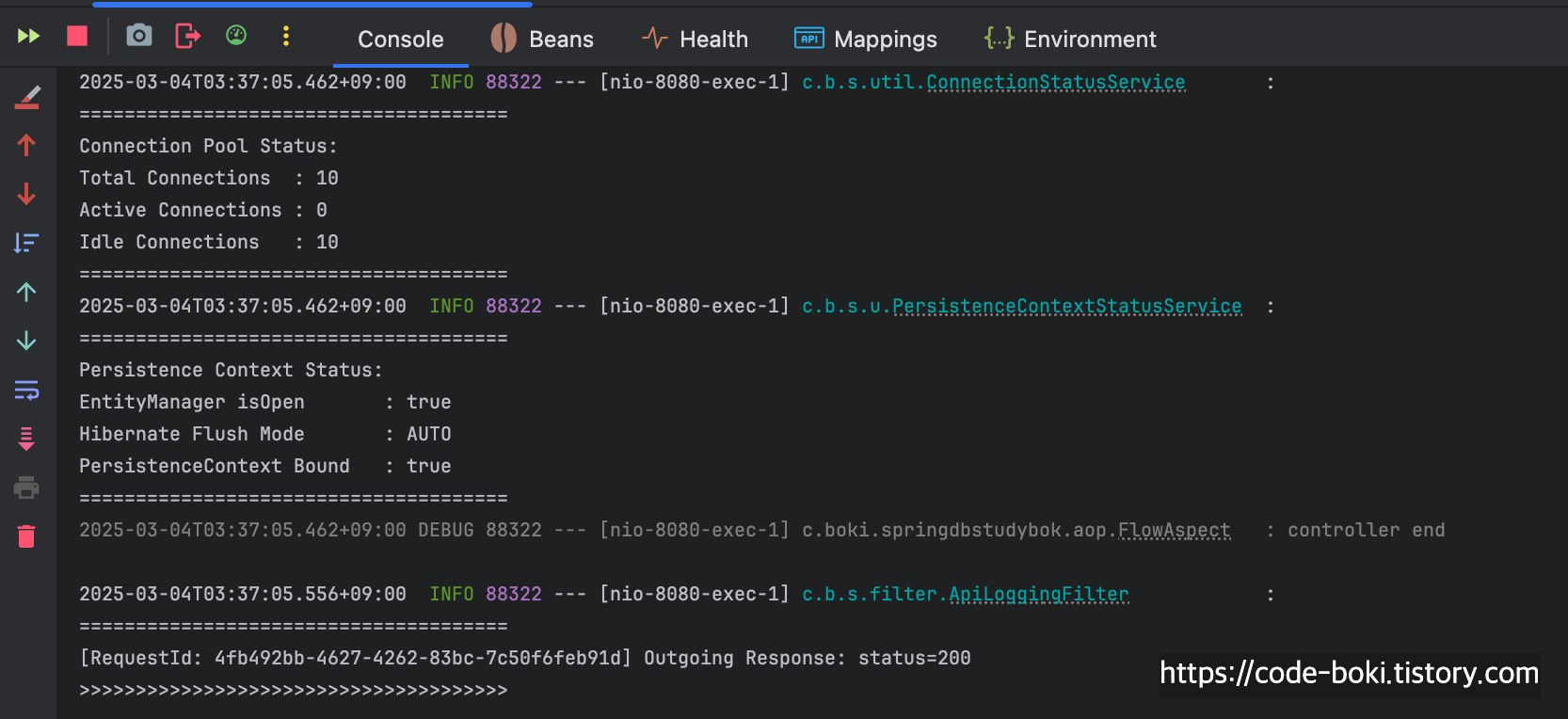
위에서 테스트했던 기본 HikariDataSource의 결과와 비교하면, 완전히 똑같다.
커넥션을 사용하지도 않았고, 트랜잭션이 활성화되지도 않았고, flush Mode도 변함이 없었다.
[ DB Conn: X(서비스/컨트롤러), Trasaction: X, Read-Only: X, Flush: Auto(서비스/컨트롤러), Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /no-query/no-tx ]
> [ 분석 시작: /no-query/tx ]
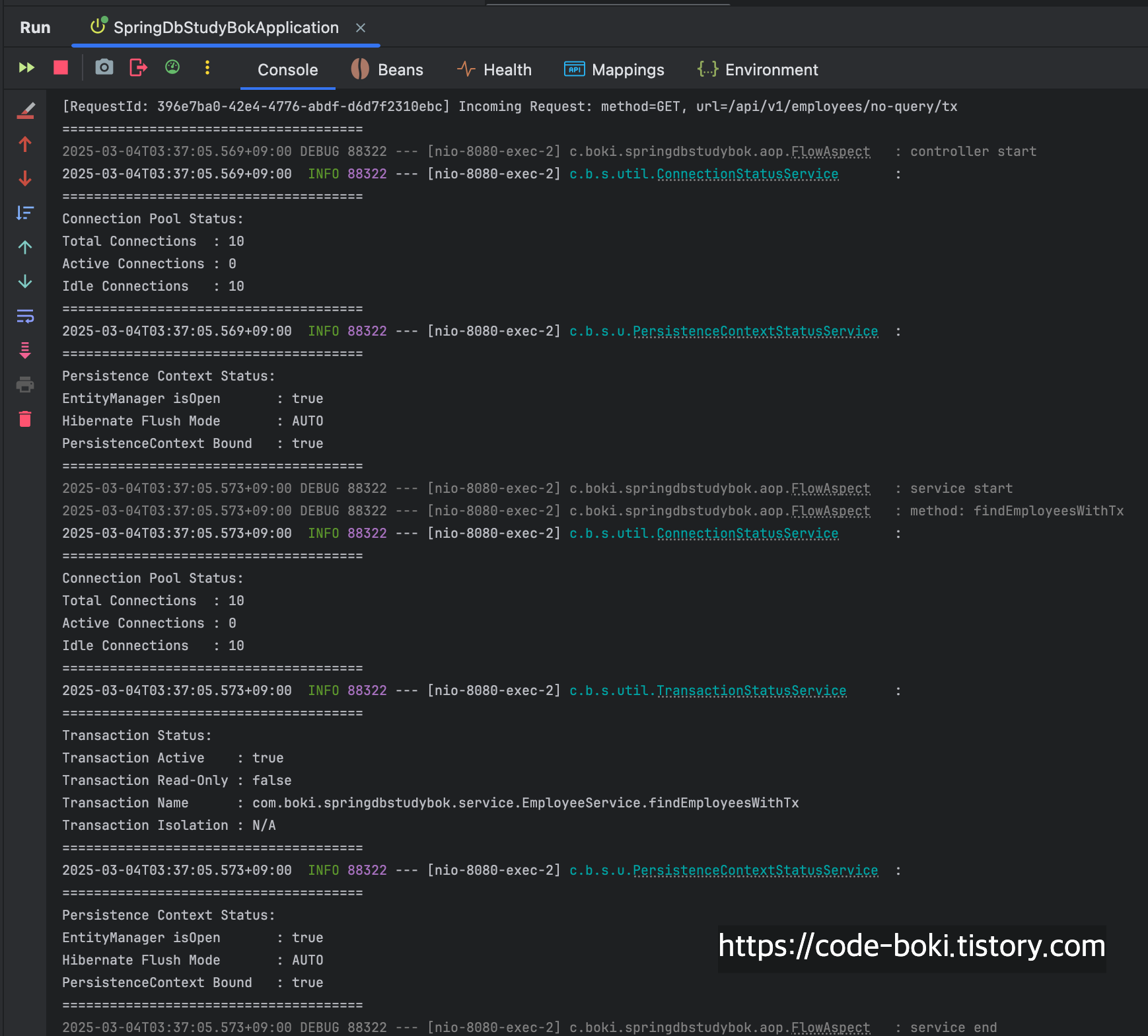
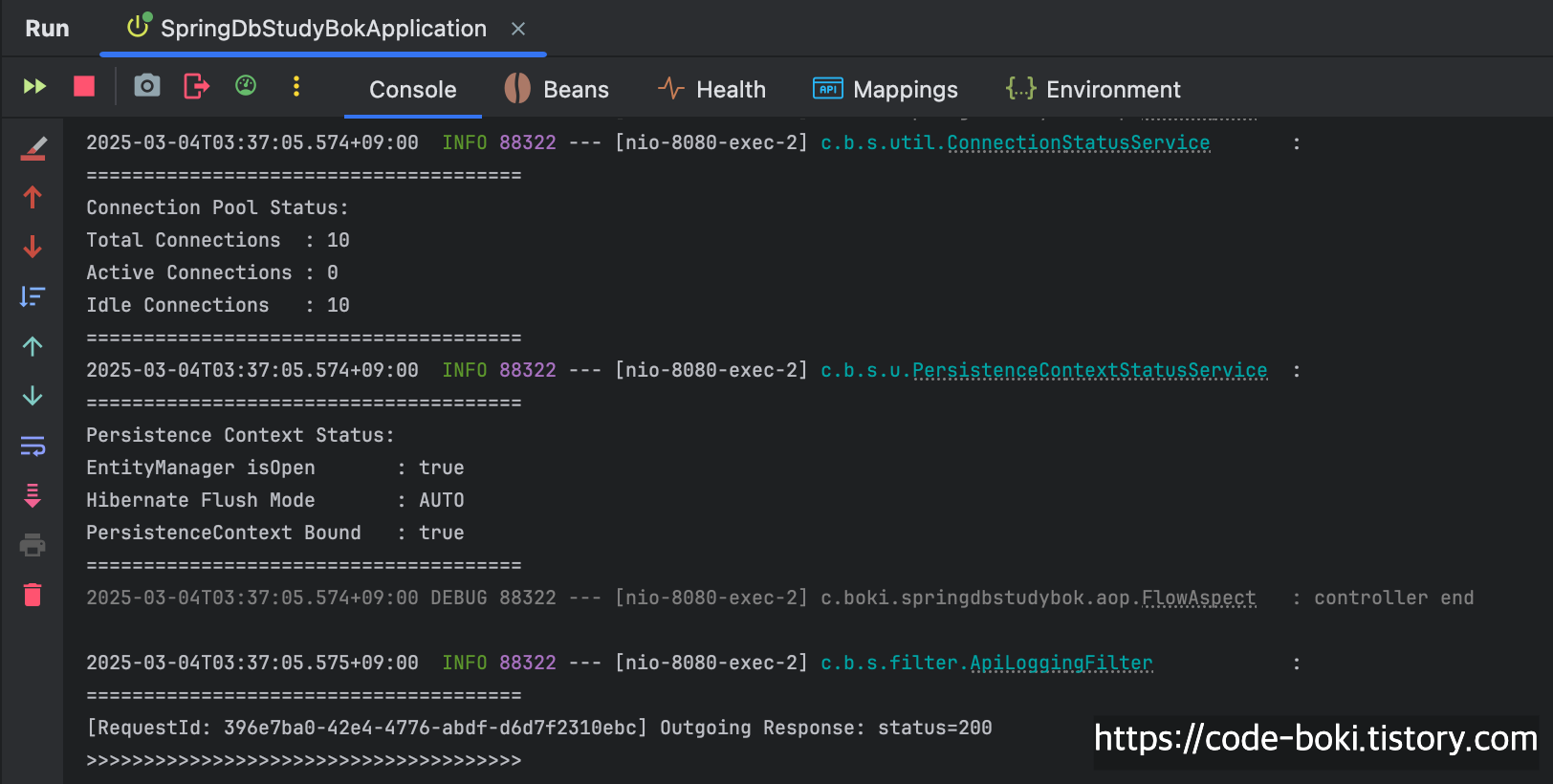
이번 테스트는 위에서 했던 HikariDataSource와 어떤 결과가 다를까?
기본 DataSource는 @Transactional이 붙어있는 메서드에서 곧바로 Connection을 Pool에서 가져다 썼다.
하지만 Query를 발생시키지 않고 Mock데이터만 응답하는 메서드에 트랜잭션을 시작한다고 하더라도, 실제 쿼리가 발생하지 않기에 Connection의 개수가 변함 없는 것을 볼 수 있다.
[ DB Conn: X(서비스/컨트롤러), Trasaction: O, Read-Only: X, Flush: Auto(서비스/컨트롤러), Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /no-query/tx ]
> [ 분석 시작: /no-query/read-tx ]

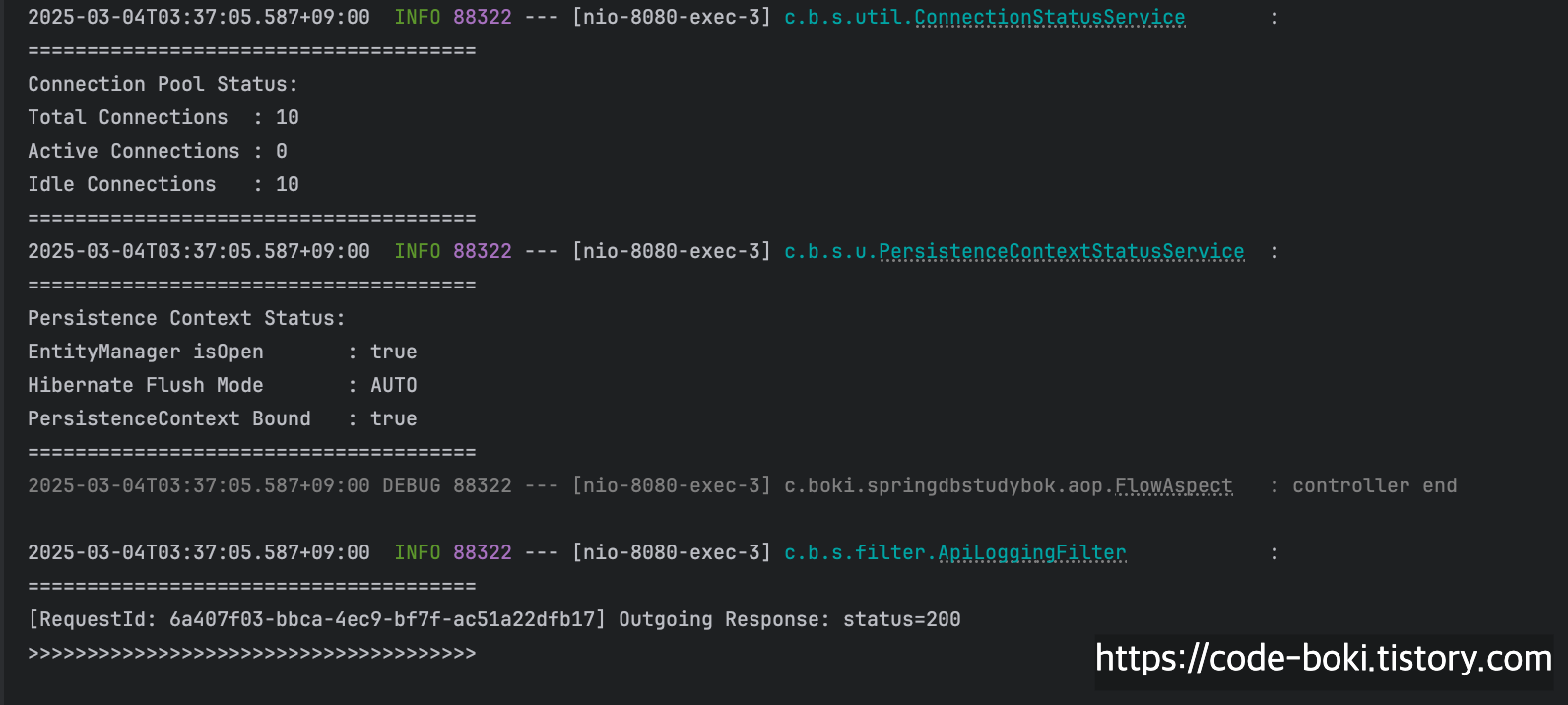
이 또한 Read Only트랜잭션만 활성화되고, 서비스 내에서 Flush Mode만 바뀔뿐 실제 쿼리가 나간게 아니기때문에 Connection의 개수는 변함이 없는 것을 알 수 있었다.
[ DB Conn: X(서비스/컨트롤러), Trasaction: O, Read-Only: O, Flush: Manual/Auto, Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /no-query/read-tx ]
- LazyConnectionDataSourceProxy + 실제 DB 정보를 반환하는 query API
a. 트랜잭션 X
b. 트랜잭션 O
c. 트랜잭션 Read-Only
실제 쿼리가 나갈수밖에 없는 상황에서는 커넥션을 소비할 것으로 예상된다. 해보자.
> [ 분석 시작: /query/no-tx ]


예상대로다. 트랜잭션이 활성화되진 않았지만, DB에 있는 데이터를 조회하기 위한 쿼리가 나갔기 때문에 커넥션을 가져와서 작업햇다.
[ DB Conn: O(서비스/컨트롤러), Trasaction: X, Read-Only: X, Flush:Auto, Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /query/no-tx ]
> [ 분석 시작: /query/tx ]
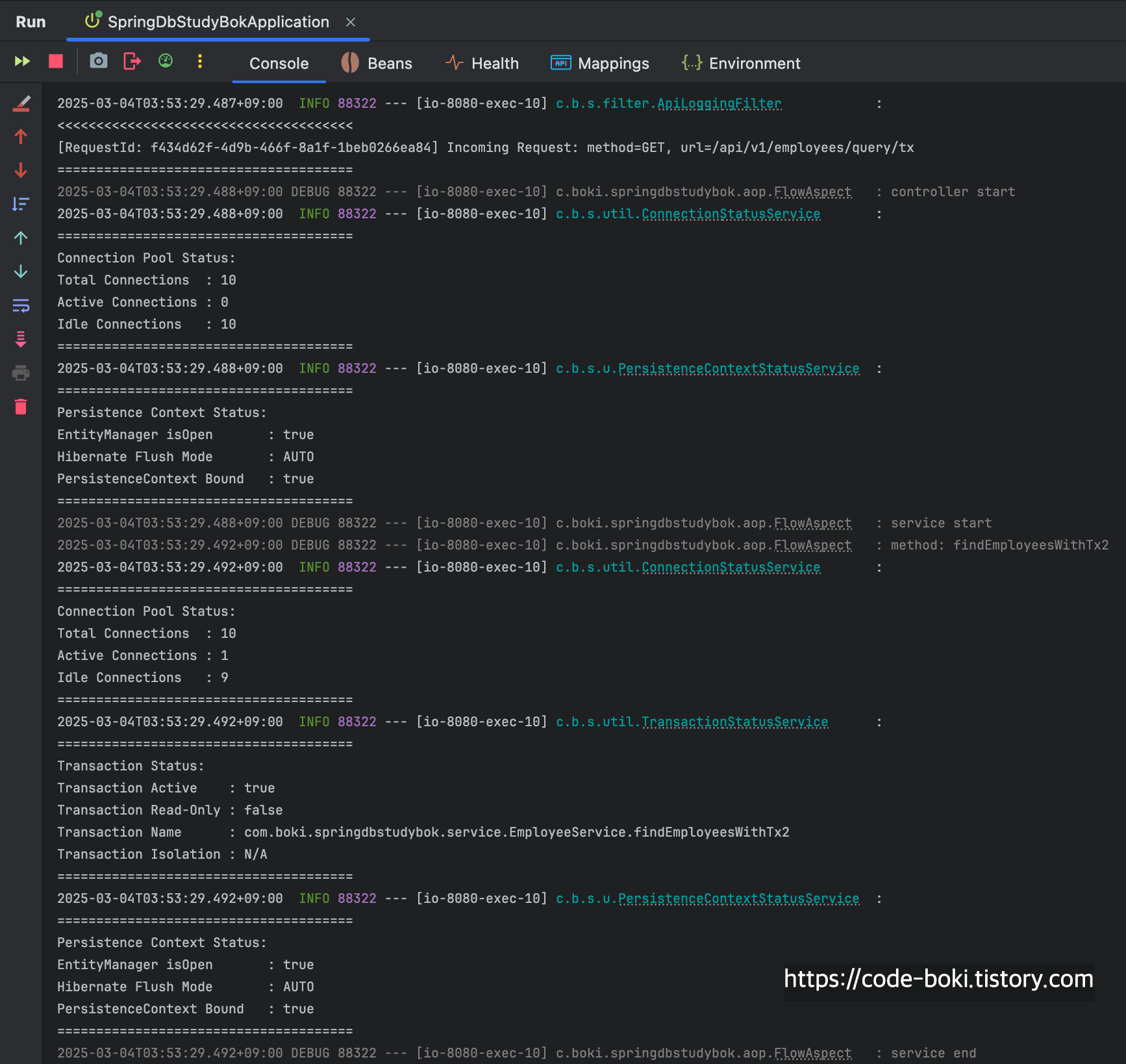
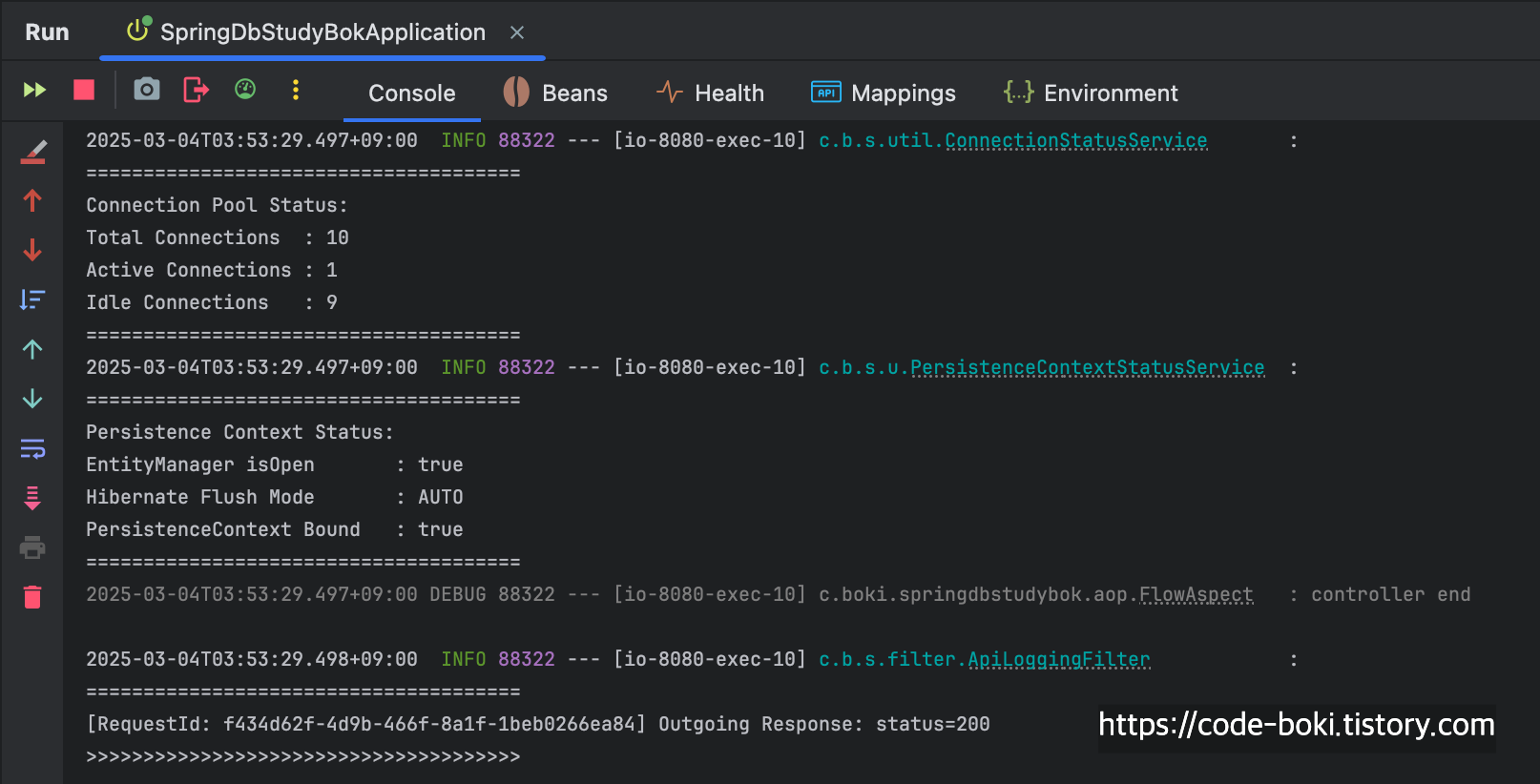
[ DB Conn: O(서비스/컨트롤러), Trasaction: O, Read-Only: X, Flush:Auto, Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /query/tx ]
> [ 분석 시작: /query/read-tx ]

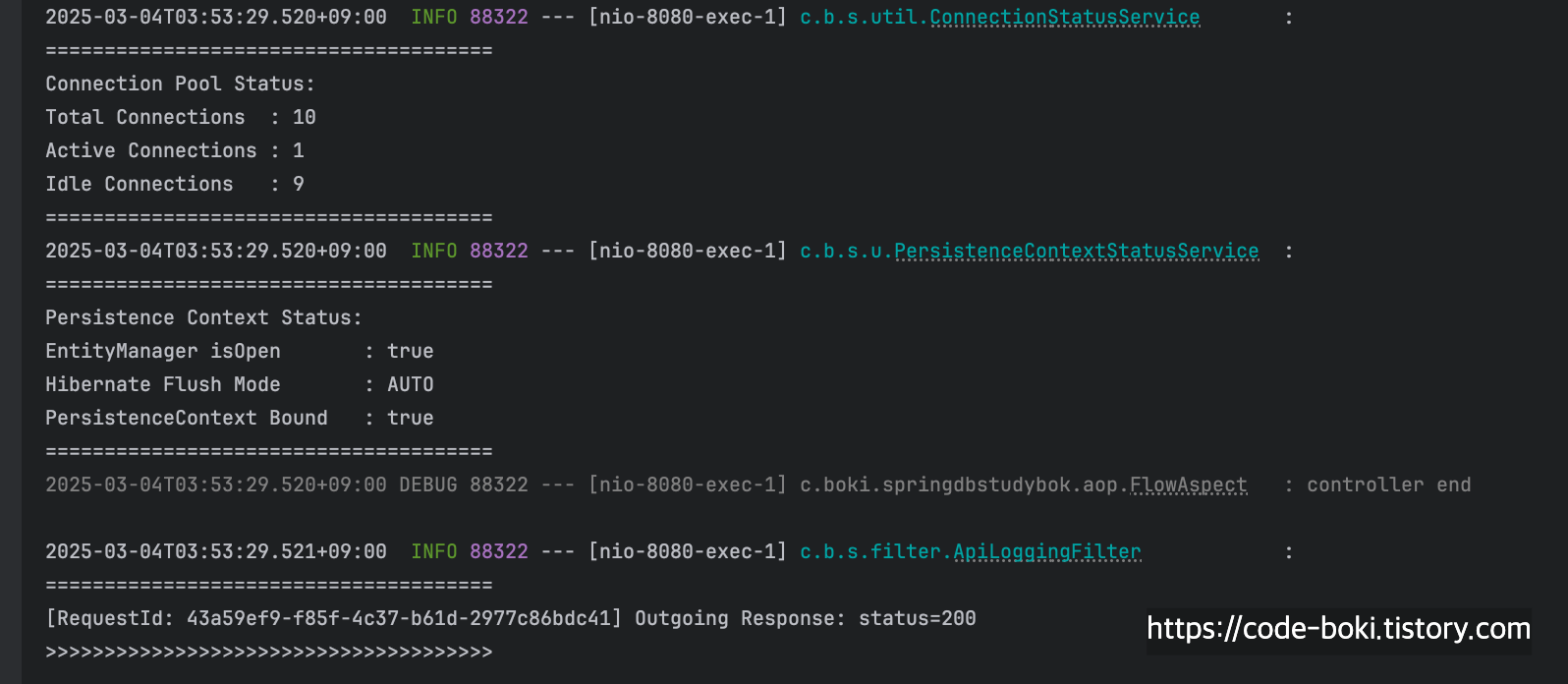
[ DB Conn: O(서비스/컨트롤러), Trasaction: O, Read-Only: O, Flush:Manual/Auto, Bound: O(서비스/컨트롤러) ]
< [ 분석 끝: /query/read-tx ]
DataSource하나만 바꿨을 뿐인데 쿼리가 발생하지 않을때는 커넥션을 사용하지 않는 등, 불필요한 커넥션 사용이 줄었다.
일단 여기까지 봤을때는 LazyConnectionDataSourceProxy를 사용하는 것이 좋아보인다.
하지만, 약간의 예상치 못한 단점이 있을 수 있다.
커넥션 획득을 실제 쿼리가 사용되는 시점까지 미루기 때문에, 트랜잭션 경계나 쿼리 실행 시점에서 약간의 지연이 발행할 수도 있다.
그리고 커넥션이 언제 실제로 획득되는지 알기 어려워, 성능 이슈를 디버깅할 때 혼란을 줄 수 있다.
고 하는데 사실 둘 다 큰 문제는 없다.
실제 쿼리가 나가야된다면 커넥션을 늦게라도 가져와서 쿼리를 실행하게 되어있고, 커넥션 갯수에만 보통 관심이 있지 획득 시점에 대해서까지 모든 개발자나 관리자가 관심을 갖지는 않을 것 같다.
결론적으로 LazyConnectionDataSourceProxy을 사용해도 좋고, 굳이 사용하지 않더라도 현재 Application의 요청량에 따른 최적의 ConnectionPool개수를 찾아서 늘려준 상태에서 HikariCP를 사용해도 상관 없어보인다.
현재
1. JDBC를 사용한 MySQL Connection Secure code & 수립 과정 살펴보기
2. Connection 비용
3. Spring/Springboot의 Connection Management
4. JPA(Hibernate)에서의 OSIV와 Connection과 상관관계
3번까지 알아봤다.
마지막으로 OSIV 옵션을 켰을 때와 껐을 때 Connection 차이에 대해서 알아보면서 4번을 분석해보자.
1. JDBC를 사용한 MySQL Connection Secure code & 수립 과정 살펴보기
2. Connection 비용
3. Spring/Springboot의 Connection Management
4. JPA(Hibernate)에서의 OSIV와 Connection과 상관관계
지금까지는 OSIV(Open-Session-In-View) 속성을 기본값인 true로 설정해놓고 테스트를 했다.
[ DB Conn, Trasaction, Read-Only, Flush, Bound ]
계속해서 테스트한 지표중에서 이 OSIV랑 관련된 지표에는 어떤 것들이 있을까??
OSIV랑 연관된 것은 DB Connection, Bound다. 과연 그런지 살펴보자!
일단, 내가 사용하고 있는 Entity인 Employee와 Department는 다음과 같다.
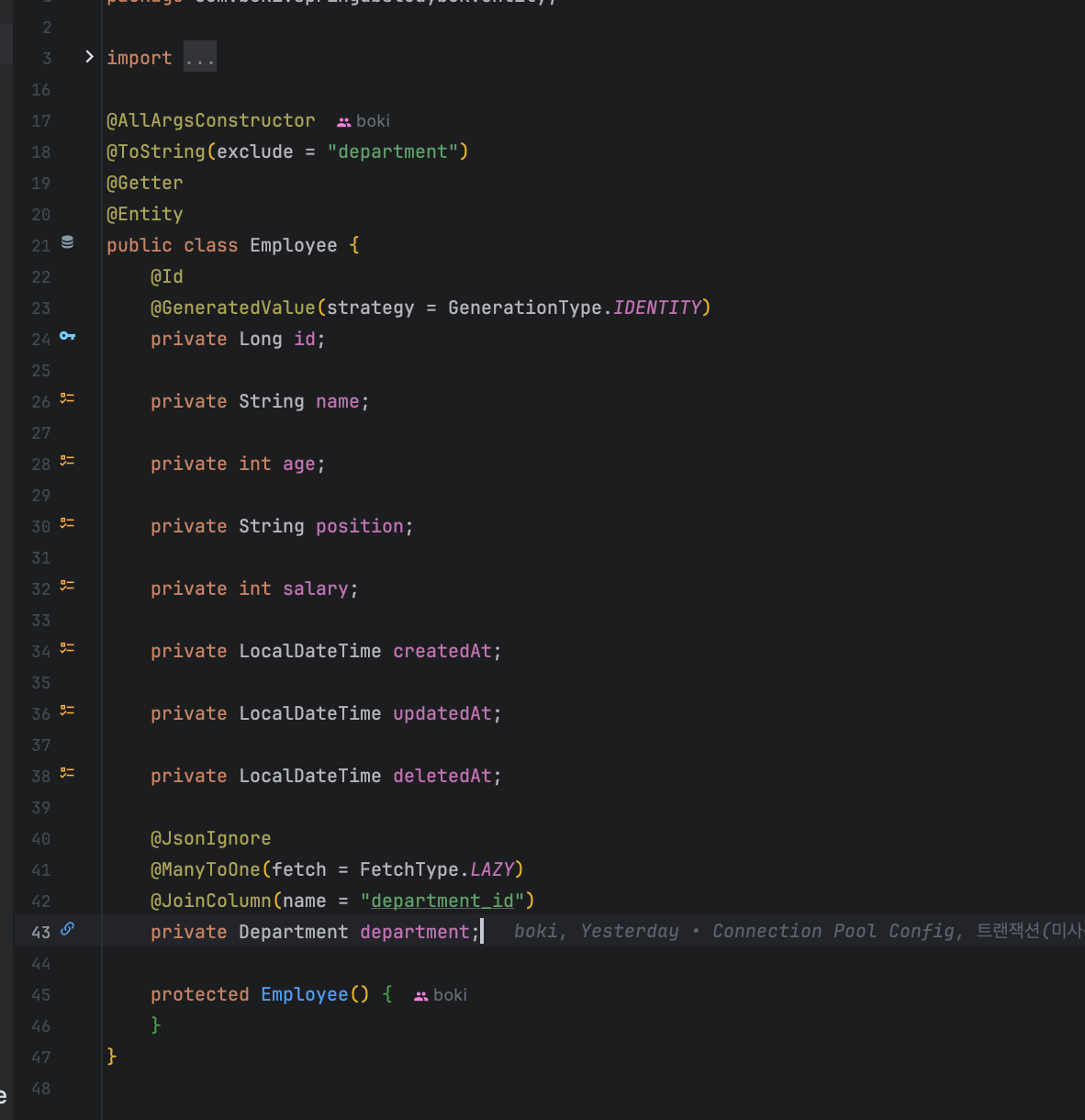
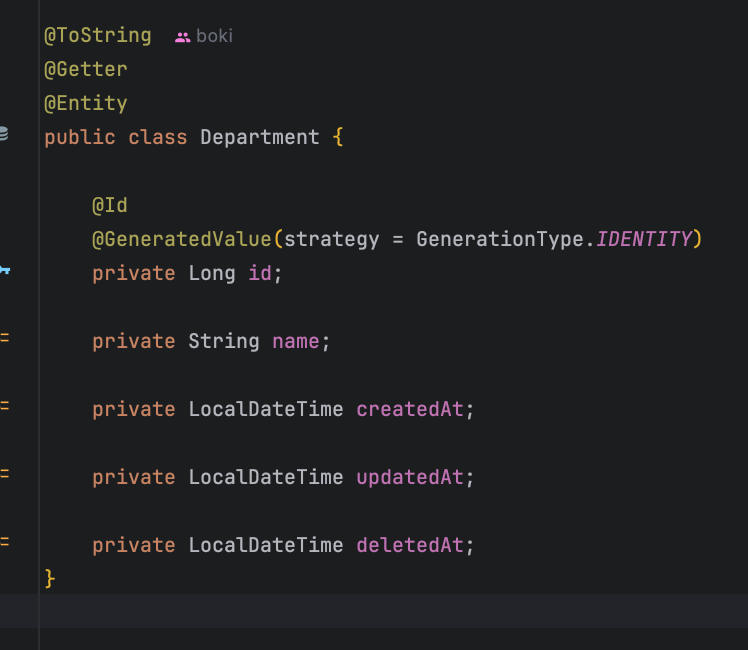
@AllArgsConstructor
@ToString(exclude = "department")
@Getter
@Entity
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int age;
private String position;
private int salary;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
private LocalDateTime deletedAt;
@JsonIgnore
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "department_id")
private Department department;
protected Employee() {
}
}
@ToString
@Getter
@Entity
public class Department {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
private LocalDateTime deletedAt;
}
원래라면 DTO를 사용해야되지만 공부목적이니깐 그냥 엔티티 자체를 응답해줬다. 이 과정에서 Department는 제외시켰다.
또한 Department 엔티티를 Employee 내에서 LAZY fetch 전략을 사용하고 있다.
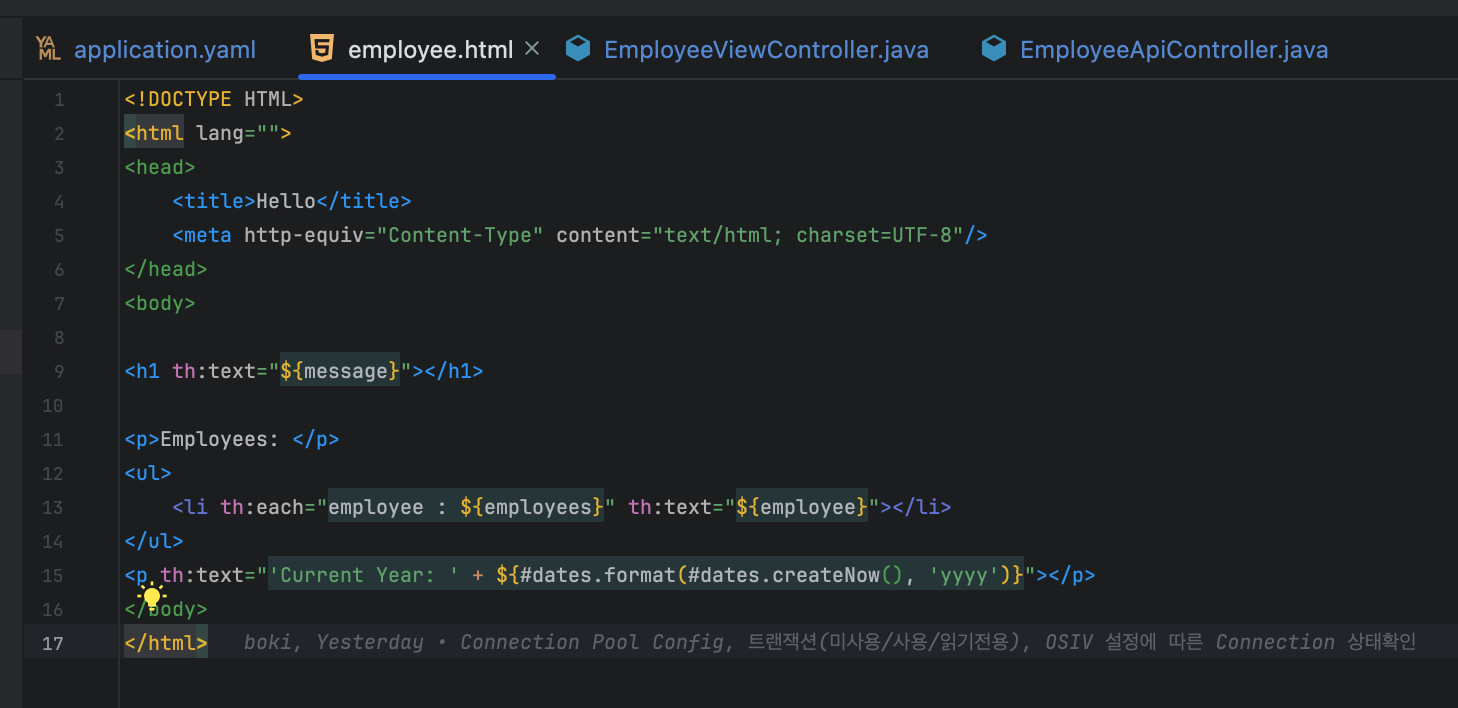
타임리프 문법을 사용한 html 문서, 그리고 $ 변수에 데이터를 담기 위해선 Model 등에 담아줘야 하기 때문에 View를 반환하는 컨트롤러도 만들었다.
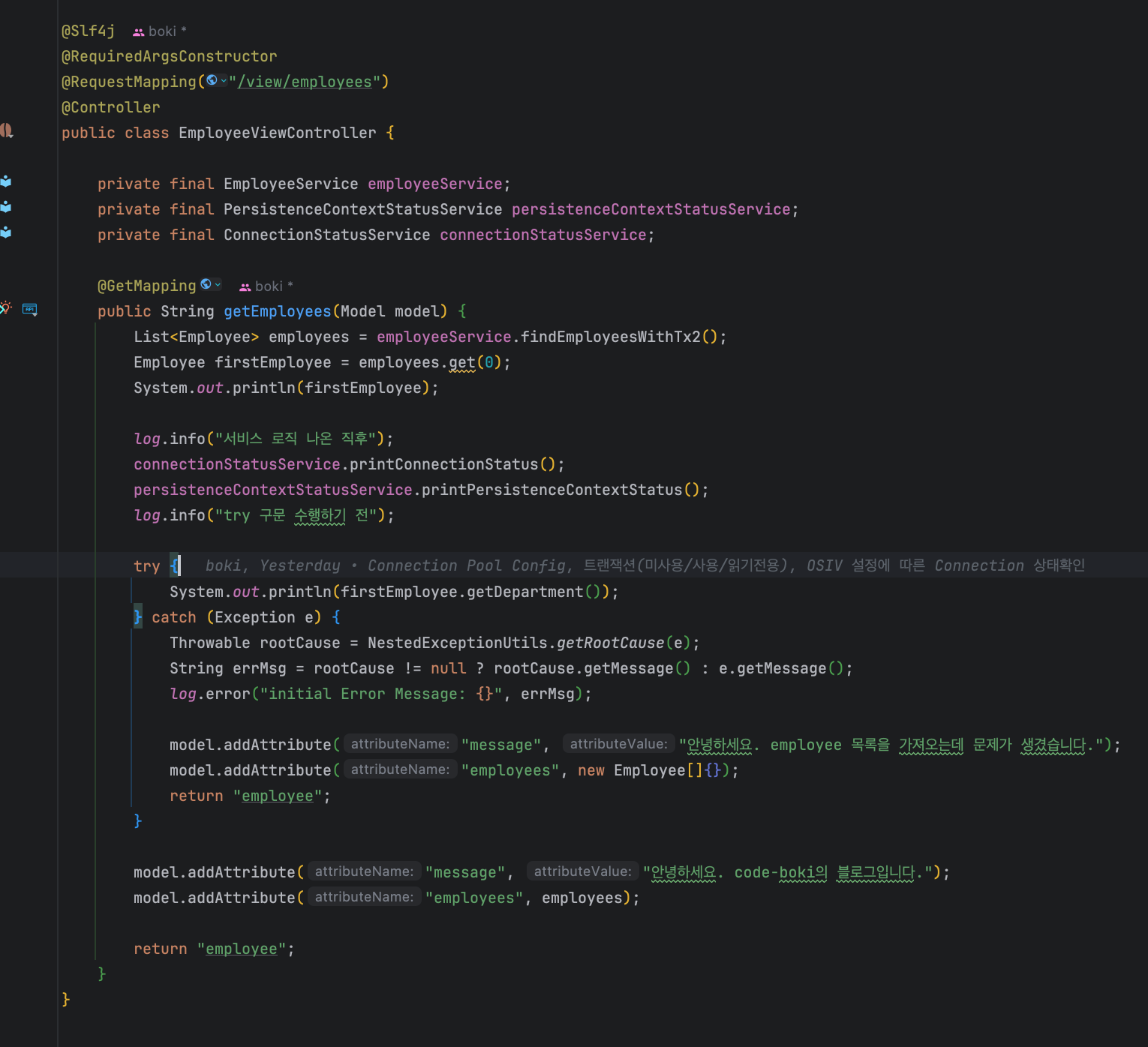
OSIV옵션에 따라 차이를 보기 위해 일부러 getDepartment()를 호출하는 코드를 추가했다.
그리고 영속성 컨텍스트와 커넥션 풀 정보를 한번 더 보기 위해 AOP와 별개로 에러가 발생하는 try구문 바로 직전에 만들어놓은 유틸 서비스를 실행시켰다.
혹여나 에러가 발생해도 화면까지 데이터가 나가는데 이상이 없어야 하기에 error로그를 찍고 throw를 하지는 않고, 빈 Employee 객체를 넘겨줬다.
- OSIV: true(spring.jpa.hibernate.open-in-view)
http://localhost:8080/view/employees로 접속하면....
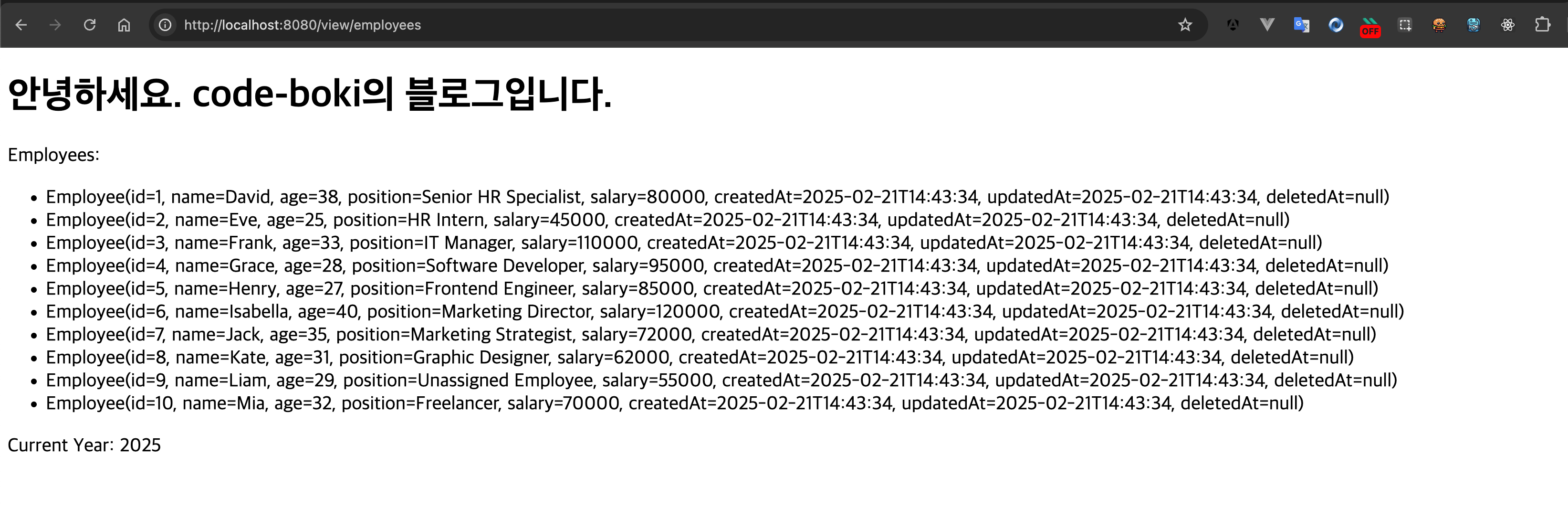
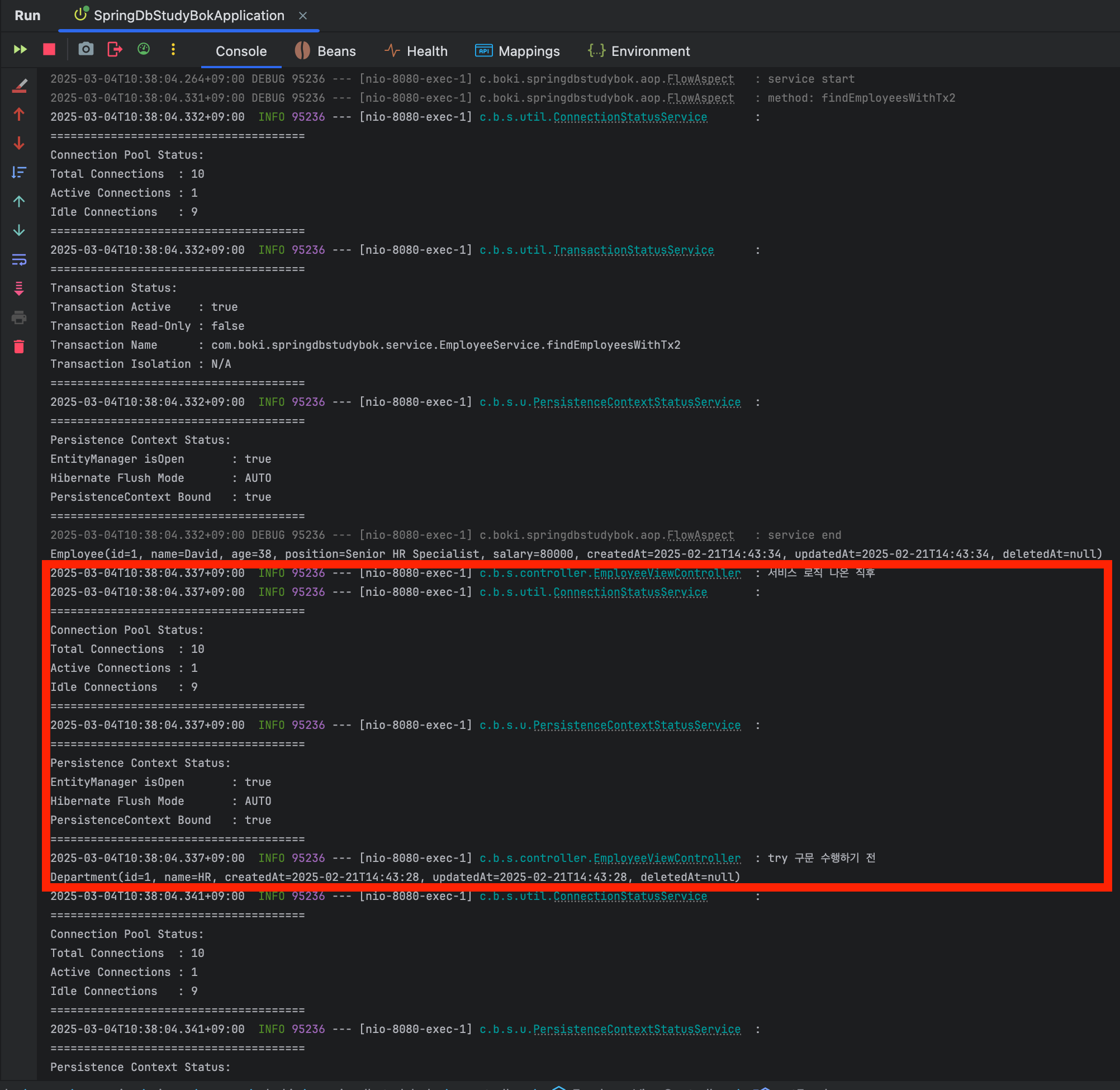
로그에서 가장 중요하게 봐야될 부분은 service end 이후의 로그이다.
Department(id=1, ...)
서비스 호출이 끝난 후의 컨트롤러단에서도 DB Connection이 아직 사용되고 있고, PersistenceContext Bound도 true이다.
그렇다면 이 속성을 false로 해놓고 다시 같은 주소로 접속해보자.
- OSIV: false(spring.jpa.hibernate.open-in-view)

화면을 보여줘야 하는 입장에서 에러만 던지면 안되기 때문에, 빈 데이터를 넘기면서 문제가 생겼다는 것을 간단하게 알려줬다.
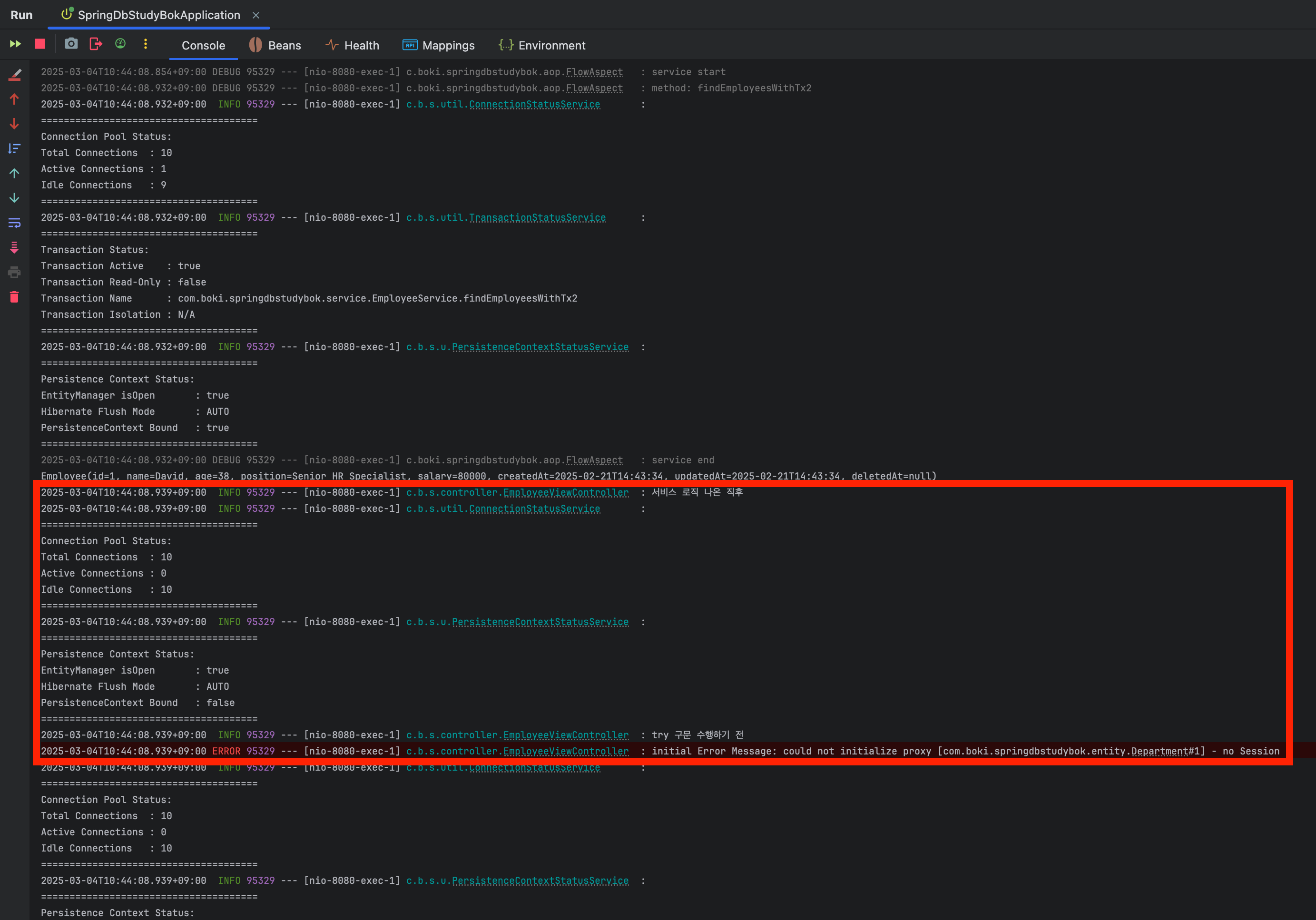
다시 로그를 살펴보면 서비스를 나온 이후, 커넥션을 반환했고, 영속성컨텍스트와 자원이 Bind되어있는 상태가 아니라는 것을 알 수 있다.
boolean isBound = TransactionSynchronizationManager.hasResource(emf);해당 로그는 내부에 위 메서드를 사용해 확인했다.
public static boolean hasResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Object value = doGetResource(actualKey);
return value != null;
}
라이브러리 내부로 들어가면 트랜잭션동기화매니저에서 위와 같은 메서드들을 사용해 결과를 반환한다.
결론적으로 OSIV를 off한 상태면 컨트롤러단에서 커넥션 뿐만아니라, 자원과의 연결도 해제된다는 것을 알 수 있었다.
Connection이라는 것이 얼마나 값비싸고, 민감한 자원인지 위에서부터 쭉 알아봤다.
- 시간/자원: TCP 연결 수립/종료, Cost
- 해결하기 위한 노력들(Application/Library Management): Connection Pool, LazyConnectionDataSourceProxy, OSIV 옵션
이번 글에서는 코드로 이해했지만, 실제로 서비스를 운영한다면 모니터링 툴과 퍼포먼스/부하 테스트 등을 통해 최적의 하드웨어 자원(CPU/Memory/DISK/Network)과 소프트웨어 자원(Thread Pool, Connection Pool, Custom Configuration)을 찾는 과정이 동반되어야 할 것이다.
'DailyLife > 글또(개발자 글쓰기 모임)' 카테고리의 다른 글
| 개발자의 필수덕목 1.Debugging(디버깅) (4) | 2025.03.16 |
|---|---|
| Hibernate(JPA) 탐구 - 2편(feat. save() 메서드 분석) (2) | 2024.12.11 |
| it, 그것을 찾아서 (5) | 2024.11.19 |





댓글